
Bringing robot skills from simulation to the real world
We should use simulation data at scale for robot foundation models

Robotics data generation is really difficult and remains a hugely unsolved problem. For general-purpose home robots, data needs to be plentiful, sure, but that data also needs to be diverse along useful axes: you want to be performing the same task on different objects in a wide variety of different environments.
You can read more about scaling for imitation learning in my last post:

So, we need tons of high quality data to train our method. Well, you could have an army of people go around collecting data in the real world — but that’s hard and expensive! Instead, increasingly, we’re seeing people turn to simulation as a solution.

If you find this kind of post useful, please subscribe below, and you can always leave a comment to let me know what you think (or add your favorite sim-to-real work I missed):
Why Simulation Data?
One challenge - which I mentioned in my previous post - is that this data also has to be high quality. That’s what’s stopping me from handing out UMI Grippers or Sticks to anyone and everyone and generating useful data. I want to use only one strategy to collect my data; I don’t want a lot of noise; this means it’s actually best if the data comes from the same person! That makes real world scaling quite hard, hence the proliferation of companies like Sensei that focus on collecting training data.

The problem is that for current imitation learning methods to scale well, data needs to be carefully curated. The approach above works, but you really need expert teleoperators (like the guy in the gif) who know what they’re doing, and that can quickly become a big cost on its own. It takes time away from people who know your system, and often it’s hard to get a truly diverse range of environments.
Simulation has huge potential for solving basically every part of this problem. Let’s talk about why.
And we’ve seen startups getting in on the action:
Hillbot is focusing on sim-to-real for shelf stocking
Scaled foundations has released AirGen, their new sim platform for robot data
Electric Sheep uses NVIDIA omniverse to train sim-to-real policies for landscaping
Skild raised an eye-watering $300 million series A on sim-to-real learning
Lucky Robots is building beautiful simulations for training robot foundation models
And this is on top of the academic wins: Poliformer, the best paper at CoRL 2024 [2], and Harmonic Mobile Manipulation, the IROS 2024 best paper [3], both were trained fully sim-to-real using AI2 Thor, using the incredible diversity of its procedurally-generated environments (see the video above). Let’s talk about why this works.
Visual Domain Randomization
Again, the key to generalizable visuomotor policy learning is data diversity.
Data quantity is important, but even more important is properly capturing and exceeding the diversity of the target distribution. This is true for both large language models like NVIDIA’s NVLM and for robot policy learning. This type of domain randomization has been widely used in the past: see DOPE [4], for example, and SORNet [5], both older NVIDIA works.
The recipe, as shown in all these videos, seems straightforward: randomize textures, room layouts, and environments, as much as possible, in order to create meaningfully diverse environments in which the robots need to learn.
When doing a task like pose estimation [4] or state classification [5], this is not so hard: the backgrounds can be randomized from MS-COCO or some other big image dataset, point lights can be moved, specularity of objects can be tweaked. It’s much harder for complex visuomotor policies like navigation and mobile manipulation, since the environment itself must be so much more complex.

Works like Robocasa[1] and ProcThor [6] solve this via procedural generation of environments. See above: ProcThor generates structure procedurally, adding doors and objects, to make complex, realistic environments at scale for robot training. And we can see that this has paid off with various follow-up works.
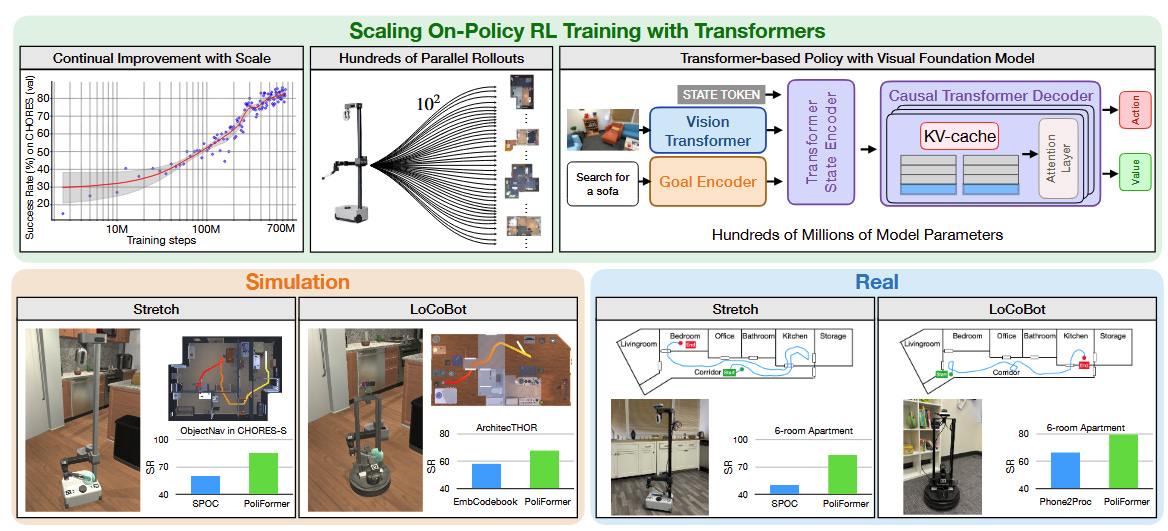
Above you can see a plot from Poliformer [2], showing how they can scale simulation training of RL agents for navigation policies that, crucially, work in the real world. Poliformer was trained from 150,000 procedurally-generated houses, using the massive Objaverse library of open-source 3d models to populate scenes.
Similar great work from AI2 showed mobile manipulation — moving and grasping — wholly from sim to real as well [3], though this was using imitation learning. There’s also some very cool and promising work on manipulation called ManipGen [9]:
All this was trained in simulation, on diverse objects and in diverse, procedurally-generated tabletop environments. The authors show generalization to a large numebr of tasks and environments, although they use a VLM to coordinate the local policies learned in this manner - more on that later.
There’s still a lot of human engineering that goes into task creation and reward design in simulation; one hopeful direction comes from projects like Eureka [7] and Eurekaverse [8], which is to use LLMs to procedurally generate tasks and reward functions. This may help scale up robot learning in simulation substantially, and has already shown some promise on sim-to-real transfer.
Final Notes
Sim-to-real is really exploding, and shows some incredible promise for training general-purpose robot policies. There are still some caveats though.
What is it still bad at?
Well, we’re not good at transferring semantics from simulation to reality. Poliformer - wonderful work that it is - uses Detic for object detection, which is trained on real world data. We saw the same thing in our own OVMM work; training policies from RGB to find open-vocabulary objects often does not work (yet). And remember ManipGen [9]? They’re training local policies, which means you still need a VLM to coordinate, you need object detectors and motion planners to move the robot into the right positions to use the skills, etc.
In the end, this suggests that, for the near future, we’ll probably be using “normal” generative AI and real-world data for out-of-distribution objects, and using sim-to-real for tasks like navigation and (some types of) policy learning. A family of models, not a single, monolithic policy - at least for now.
Stuff I deliberately left out
There’s a lot of work in sim-to-real that focuses on using depth. A lot of great work from NVIDIA does this, for example, like DextaH-G [10], as well as really great navigation work like Navigating to Objects in the Real world [11]. I didn’t focus on works like Dextreme [12] or Deepmind’s soccer-playing robots [13] without as strong an environment randomization component, though they’re worth reading about.
Maybe next time.
Remember to share and subscribe if you liked this:
And leave a comment if you feel I have left something important out or have thoughts about what I should cover next in this space.
References
[1] Nasiriany, S., Maddukuri, A., Zhang, L., Parikh, A., Lo, A., Joshi, A., ... & Zhu, Y. (2024). RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots. arXiv preprint arXiv:2406.02523.
[2] Zeng, K. H., Zhang, Z., Ehsani, K., Hendrix, R., Salvador, J., Herrasti, A., ... & Weihs, L. (2024). PoliFormer: Scaling On-Policy RL with Transformers Results in Masterful Navigators. arXiv preprint arXiv:2406.20083.
[3] Yang, R., Kim, Y., Hendrix, R., Kembhavi, A., Wang, X., & Ehsani, K. (2023). Harmonic mobile manipulation. arXiv preprint arXiv:2312.06639.
[4] Tremblay, J., To, T., Sundaralingam, B., Xiang, Y., Fox, D., & Birchfield, S. (2018). Deep object pose estimation for semantic robotic grasping of household objects. arXiv preprint arXiv:1809.10790.
[5] Yuan, W., Paxton, C., Desingh, K., & Fox, D. (2022, January). Sornet: Spatial object-centric representations for sequential manipulation. In Conference on Robot Learning (pp. 148-157). PMLR.
[6] Deitke, M., VanderBilt, E., Herrasti, A., Weihs, L., Ehsani, K., Salvador, J., ... & Mottaghi, R. (2022). 🏘️ ProcTHOR: Large-Scale Embodied AI Using Procedural Generation. Advances in Neural Information Processing Systems, 35, 5982-5994.
[7] Ma, Y. J., Liang, W., Wang, G., Huang, D. A., Bastani, O., Jayaraman, D., ... & Anandkumar, A. (2023). Eureka: Human-level reward design via coding large language models. arXiv preprint arXiv:2310.12931.
[8] Liang, W., Wang, S., Wang, H. J., Bastani, O., Jayaraman, D., & Ma, Y. J. (2024). Eurekaverse: Environment Curriculum Generation via Large Language Models. arXiv preprint arXiv:2411.01775.
[9] Dalal, M., Liu, M., Talbott, W., Chen, C., Pathak, D., Zhang, J., & Salakhutdinov, R. (2024). Local Policies Enable Zero-shot Long-horizon Manipulation. arXiv preprint arXiv:2410.22332.
[10] Lum, T. G. W., Matak, M., Makoviychuk, V., Handa, A., Allshire, A., Hermans, T., ... & Van Wyk, K. (2024). Dextrah-g: Pixels-to-action dexterous arm-hand grasping with geometric fabrics. arXiv preprint arXiv:2407.02274.
[11] Gervet, T., Chintala, S., Batra, D., Malik, J., & Chaplot, D. S. (2023). Navigating to objects in the real world. Science Robotics, 8(79), eadf6991.
[12] Handa, A., Allshire, A., Makoviychuk, V., Petrenko, A., Singh, R., Liu, J., ... & Narang, Y. (2023, May). Dextreme: Transfer of agile in-hand manipulation from simulation to reality. In 2023 IEEE International Conference on Robotics and Automation (ICRA) (pp. 5977-5984). IEEE.
[13] Haarnoja, T., Moran, B., Lever, G., Huang, S. H., Tirumala, D., Humplik, J., ... & Heess, N. (2024). Learning agile soccer skills for a bipedal robot with deep reinforcement learning. Science Robotics, 9(89), eadi8022.
At what level of granularity is data, say for humanoids, useful?
I'm trying to think if a dumb way of scaling this is to just open a large warehouse in a country where labor is cheap, divide it into 100s of rooms with green screens, have people do different tasks, etc.
If we can infer the required granularity with just cameras then it wouldn't be that expensive either