
Learning Robust Visual Features for Object Understanding
What useful features for robot planning from perception look like and how we learn them. Going over Dino, CLIP, and Siglip.

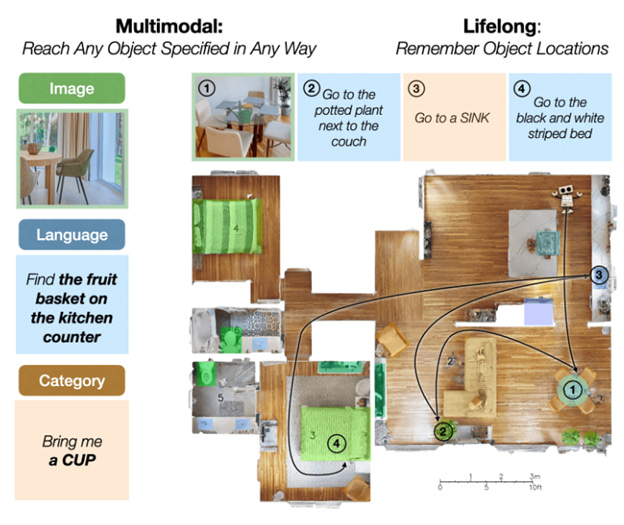
Let’s say that I want to have a robot move around in the world, find objects, *reason* about objects, and figure out what to do with them. It’ll need to understand which objects I care about, what they look like, etc. It might want to understand the meaning of rooms and places in the world.
There are a couple ways we might do this. We might learn some large end-to-end policy which can move to objects and perform different tasks. However, this takes a large amount of data, struggles to generalize, etc [2].
So instead we look at modular representations. In a modular stack, we use different models for different roles that they’re best suited for. In this and upcoming posts, I’m going to look at spatially-organized representations, i.e. maps, and how we can build them using off-the-shelf pretrained features.
In this post, I’m going to go over a few different types of pretrained visual features we’ve seen used in various works in the past: CLIP, DinoV2, and Siglip. But first, let me explain specifically what this task is and why we’re able to use them zero-shot for robotics tasks.
The starting point is this:

This is SAM2, predicting object segmentations. What’s relevant here is that segmentation models have a really strong notion of objectness, which means that it’s pretty easy now to break up a scene reliably into various parts. SAM2 is an incredible accomplishment; the problem that we have, as roboticists or builders of intelligent AI agents, is going to be building cool applications on top of this. That necessitates understanding what things actually are.
The Problem
We want robots that can execute long-horizon, open-vocabulary tasks in any environment without extensive pretraining. That is, I should be able to unpack my robot, tell it to do something, and have it do that thing. We’ll consider the subset of tasks called open-vocabulary mobile manipulation [3]: finding, picking, and placing objects from different locations around the home.
To do this, we want some set of features that let us differentiate which objects refer to which. This is zero-shot classification, and at its simplest level in robotics it looks like this:

In [4] we used CLIP features to differentiate between different objects based on open-vocab language instructions that were sometimes quite hard. We trained a model on top of it (LaGOR in the image above) but honestly you don’t need to do that.
So, now the problem is clear: I want some set of features that help me uniquely identify objects in the world, zero-shot, so that I can do things with them. So let’s go into some options.
The Models
So I’m interested in features that work “out of the box,” basically that don’t — at least initially — need any fine-tuning to get them to work.
I’ll discuss three ways of learning features in this post: CLIP from OpenAI, Siglip from Google, and DinoV2 from Meta. And hey, isn’t that list of creators just a summary of the state of our field right now.
Contrastive Language Image Pretraining (CLIP)

CLIP was a huge deal when it was released by OpenAI. The core idea is that the internet is filled with image-text pairs — captioned images like the ones you’re seeing in this very document, for example. CLIP is a highly efficient way of training features for images and text, so that they agree. This is done by having completely separate image and text encoders, which are related via cosine similarity. Pseudocode from the paper:
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# extract feature representations of each modality
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# joint multimodal embedding [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# scaled pairwise cosine similarities [n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# symmetric loss function
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2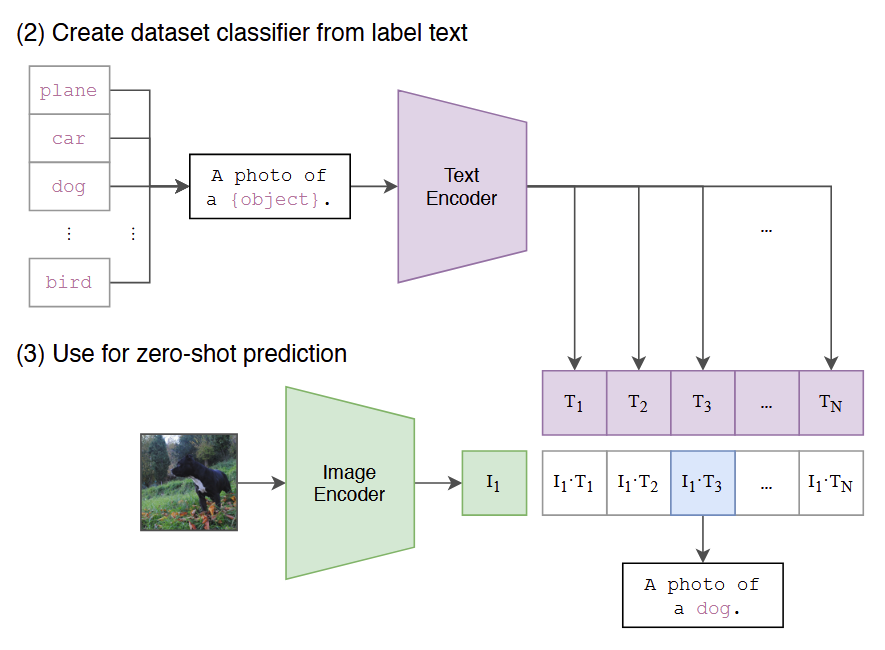
So, in effect, we’re just taking our image and text encoders and then doing a dot-product over them. Nice and easy, and because these two things are totally independent, it’s nice and efficient as well.
The obvious use for this is zero-shot image classification, as you can see above. Give a list of objects or even concepts (plane ,car, dog, bird, etc.), and you can easily distinguish between them.
Hopefully it’s obvious how that’s useful for robots. Above, you can see an example of Gemini, a dialogue-based agent that I worked on briefly at NVIDIA. It’s using CLIP features for basically everything here - identifying object qualities and understanding the scene so that it can interact with people.
SigLIP
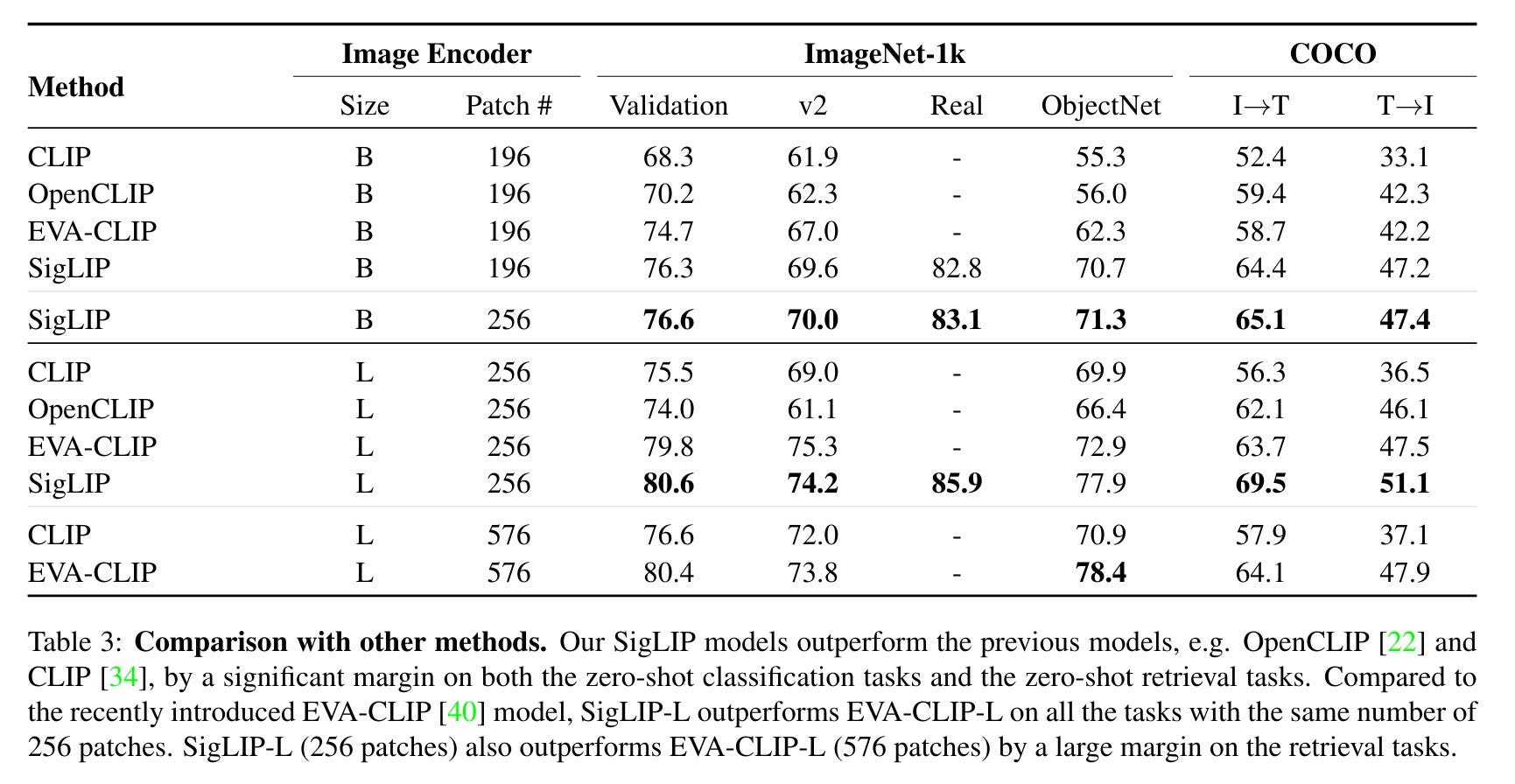
One notable improvement over CLIP is SigLIP [8], which is a Sigmoid loss for language image pretraining proposed by google researchers. It has two big advantages:
Better performance (of course) - see the plot above.
More efficient training.
The basic idea is that they pose it as a binary classification problem, where you predict each term individually:

The fact that this is a binary classification problem instead of a comparison like the original CLIP might also help for robotics use cases in general, where we don’t know if the object is in the scene.
The sigmoid loss they propose makes each term in the loss independent, which means that you can split it across devices and compute it more efficiently than the original CLIP, which needs a giant matrix. Great!
Limitations
This doesn’t generalize amazingly well - but I mean what does? Fortunately you can train it on so much stuff that it doesn’t matter.
CLIP also fails badly at spatial concepts, especially things like “left” and “right,” and it isn’t all that complex. Generally it’s going to function as an “or”, responding more to one term in something (query for “white coffee cup,” and the model will often select “white” objects and “cup” objects, not “white coffee cup” objects). It’s also NOT a detector, just a classifier, so you need a set of options; if none match it just tells you which one is best.
Another huge limitation — going back to our original problem — is that models like CLIP features treat different views of the same object differently. Remember, the loss discussed above is explicitly comparing language to an image.
Why do I care about that? Well, a few reasons:
The robot might see the same object from different angles - we can use this to de-duplicate the object, confirming there is one or more of a particular type of thing on the table. Useful for planning and reasoning.
The robot might pick up and object, move it to some new location, and have it settle slightly off from
The robot might not pick up anything, but a human might! The object might be moved around and we should still be able to say, “oh, that’s the same thing I saw earlier.”
CLIP works for none of this!
Dino v2
Alright, so we’ve discussed image-language aligned features. DinoV2 is a set of pretrained features for image understanding, but with a slightly different goal.

The goal of dino is to learn robust visual features through self-supervised learning, as a form of pretraining for downstream learning of more complex models [7]. This is slightly different from the CLIP case above, which is supervised learning: we know which text matches to which image, even if, because it’s all webscale data, a lot of this matching will not be very good. It’s also noteworthy that, while I care about the underlying properties of the features we’re learning, that’s not really the point of this paper we’re discussing.
This is a much, much more complex paper than CLIP, at least in my opinion, without the same clean summary we saw above, but I’m going to do my best here. The idea is we have a student and a teacher network, and the image-level objective is going to be to force these two to align:

The teacher is given better, higher-resolution views of an object; the student is given worse, lower-resolution views, and different parts of the image are masked out. There’s both an image-level head and a patch-level head on the model, similar to the above.
Uniquely, the teacher network is not a pretrained model: its constructed out of a moving average of previous student networks.
So, we’re enforcing that for every image, if you corrupt it, look at low res versions of it, shift it and augment it, it’ll have the same representation. This lets us learn robust features that are good for comparing images to each other, instead of images to images as in CLIP above.
Summary
Vision pretraining is going to be a huge part of what makes robotics work in the real world. We have a situation where language and image features are getting quite powerful, and actually work “out of the box” for many applications.
Next week, I’ll talk about what we can build with these things and look into some papers on scene graphs.
References
[1] Chang, M., Gervet, T., Khanna, M., Yenamandra, S., Shah, D., Min, S. Y., ... & Chaplot, D. S. (2023). Goat: Go to any thing. arXiv preprint arXiv:2311.06430.
[2] Gervet, T., Chintala, S., Batra, D., Malik, J., & Chaplot, D. S. (2023). Navigating to objects in the real world. Science Robotics, 8(79), eadf6991.
[3] Yenamandra, S., Ramachandran, A., Yadav, K., Wang, A., Khanna, M., Gervet, T., ... & Paxton, C. (2023). Homerobot: Open-vocabulary mobile manipulation. arXiv preprint arXiv:2306.11565.
[4] Thomason, J., Shridhar, M., Bisk, Y., Paxton, C., & Zettlemoyer, L. (2022, January). Language grounding with 3d objects. In Conference on Robot Learning (pp. 1691-1701). PMLR.
[5] Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., ... & Sutskever, I. (2021, July). Learning transferable visual models from natural language supervision. In International conference on machine learning (pp. 8748-8763). PMLR.
[6] Ravi, N., Gabeur, V., Hu, Y. T., Hu, R., Ryali, C., Ma, T., ... & Feichtenhofer, C. (2024). Sam 2: Segment anything in images and videos. arXiv preprint arXiv:2408.00714.
[7] Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., ... & Bojanowski, P. (2023). Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193.
[8] Zhai, X., Mustafa, B., Kolesnikov, A., & Beyer, L. (2023). Sigmoid loss for language image pre-training. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 11975-11986).