
Maybe Data Really is All You Need
The biggest debate in robotics is about whether or not scaling will "solve" the field; regardless to the answer to that, access to data is driving changes in the field

At the International Conference on Robotics and Automation (ICRA) in Atlanta, Georgia, a group of esteemed roboticists gathered on stage to discuss what is perhaps the most pressing question in robotics right now: is data enough to solve robotics?
The largest robotics research conference in the world culminated, unusually, in an on-stage debate focused on one of the most important topics in our field, organized and hosted by Ken Goldberg of UC Berkeley. Arrayed on both sides were luminaries from the robotics research field; people like Russ Tedrake of the Toyota Research Institute and Aude Billard of ETH Zurich. The massive auditorium at the Georgia World Conference Center was packed.
And there were passionate arguments from both sides! What does it even mean to “solve robotics,” anyway? Will we truly understand robotics if we just throw data at the problem, or will we be reduced to merely characterizing complex systems through careful analysis, like mere biologists? Should you throw out your Intro to Robotics textbook now, or might it have a role to serve in this data driven future?
But, regardless of the outcome of the debate, in a few ways the outcome seems clear.
Data, I think, is going to solve robotics. Eventually.
And certainly, what’s driving the current explosion in robotics is data. And that excitement really starts, in a massive way, with one thing. Let me explain.
ALOHA means…
Two papers, to me, define our current period in data-driven robotics learning more than anything. They’ve inspired waves of successors, and led to a small army of startups which are busy collecting embodied AI data and packaging it to train bigger and better models. These are:
“Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware (ALOHA),” by Tony Zhao et al., and
“Universal Manipulation Interface (UMI): In-The-Wild Robot Teaching Without In-The-Wild Robots”, by Cheng Chi., et al.
Henceforth referred to as “ALOHA” and “UMI.”
Now, a couple other key things happened too, of course. There was the line of vision-language-action models, most notably Open X Embodiment (and OpenVLA, and Octo, and so on…) but those didn’t really work. There was Diffusion Policy, which was an amazing advance in imitation learning. So why do I think these two were more significant?
Because they made data collection really, really easy. They showed how anyone could collect a fairly large dataset. And, as has been said before, there are no new problems in machine learning, only new datasets; the data is what robotics was missing all this time. These two papers took real, large, concrete steps towards solving that problem.
Diffusion Policy, amazing as it is, was not a step change in how we did robotics research, because it left you stuck with kinesthetic teaching of your huge, heavy, $30,000 Franka Panda robot arm with its awful kinematics and its terrible software. We were never going to collect meaningful amounts of data using the Franka arm (though noble attempts have been made).
ALOHA, though? You can take that anywhere. You can put it on a mobile base, for example. UMI, too, can be made dexterous, extended to many different tasks, improved and modified. You can actually do stuff with it.
In the end, you solve robotics problems by doing stuff with robots; these papers made it easy to do stuff with robots.
Data Collection For Everyone
ALOHA, in particular, was a paper that came at just the right time. Robotics hardware was getting cheaper and high-quality compute was getting more accessible, but the SayCan era of robotics was ending.
SayCan, if you do not remember (or weren’t in robotics at the time), was a massive deal back in about 2021. It used the Google PaLM large language model (LLM) to “ground” robot actions, choosing which ones to execute next given a prompt. PaLM, not Gemini, because this was Google Research, not Deepmind, back before the explosive growth of LLMs really rewrote the global tech scene.
Unfortunately, though, it was really limited. The skills only worked in certain contexts. Stringing skills together didn’t work so well. It hardly generalized. Navigation was done via a classical planner to hard-coded locations. Basically, the thing barely worked; it was just the first time people had seen really open-vocabulary language lead to a wide variety of robot actions, and it made for some killer videos (by the standards of its time, at least).
People spent a lot of time using GPT for everything robotics related. I definitely got in on this myself. But the fundamental problems of actually making robots do stuff were not solved, because those required robot data, and lots of people actually just plugging away using robots for different things.
Fortunately, throughout all of this time, robots were getting cheaper. Compute was becoming more broadly available. And researchers continued to work on the hard problems of robotics.
Papers like Diffusion Policy showed that you could use transformers to get really, really good imitation learning — high quality, dynamic motion. But what ALOHA (and later UMI) both showed, importantly, is that you didn’t need a $30,000 arm to do it. A full four-armed Trossen Mobile Aloha kit costs a bit over $30,000 — that’s about what it cost to buy a single robot arm when I was in grad school. And you’re getting something which, while a lot less repeatable, can accomplish a whole lot more tasks!
Models like RT-2 from Google showed that large vision-language transformers could accomplish a lot of the task complexity we saw from SayCan. Its follow-up, RT-X, was well into the ALOHA/low-cost robots era, as you can see in the video above. Still clumsy, still jerky — the Diffusion Transfomer component from future large Vision-Language-Action models is missing — but we’re starting to see how this takeoff is going to happen.
And the startup scene absolutely exploded. Companies like Weave Robotics seem to have started out with Mobile ALOHA style bots. Many cheap robots followed: the Koch Arm from Tau Robotics was an early example, using ACT/Diffusion Policy for a variety of really impressive manipulation tasks with extremely low cost robots:
Another great example is 7x robotics, who are building autonomous home robots to do things like fold your clothes and clean your dishes. They’re planning to sell their robots for $3000 - something that would have been unthinkable a couple years ago.
“In the Wild” Data

But now let’s talk about the other half of this. Robots have increasingly been leaving the lab. As much as there are scaling laws for robotics, they will require much more diverse data than we can get in a laboratory setting, as I’ve written about before.
What are the data scaling laws for imitation learning in robotics?

There are a lot of expensive parts to running an AI-in-robotics company. Data is expensive and time-consuming to collect. Compute is expensive. Infrastructure needs to be build out. To make big investments in learning, we want to understand the payoff.
One way to do this is with tools; that way, you don’t need to wheel around a huge robot everywhere you go. So, even as robots are getting cheaper, we see a second line of work accelerate, which uses specially-designed tools, sensors, or wearables to collect data which can be immediately transferred to a robot.

Again, though, the story is about making robot data collection easy so that you can collect more data — and importantly, diverse data, in a wide range of environments, varying all of the parameters we need to vary for good robot performance.
Recent follow-ups include DexUMI and DexWild, for learning dexterous multi-finger behaviors for robot hands. We actually had DexWild on our podcast, RoboPapers, as well — watch the episode to learn more.
Vision, Language, and Action
And this brings us to the Vision Language Action model (or Large Behavior Model if you work at Toyota, I guess). The VLA is the modern robotic version of a large multimodal model like GPT, and they all look roughly like this:
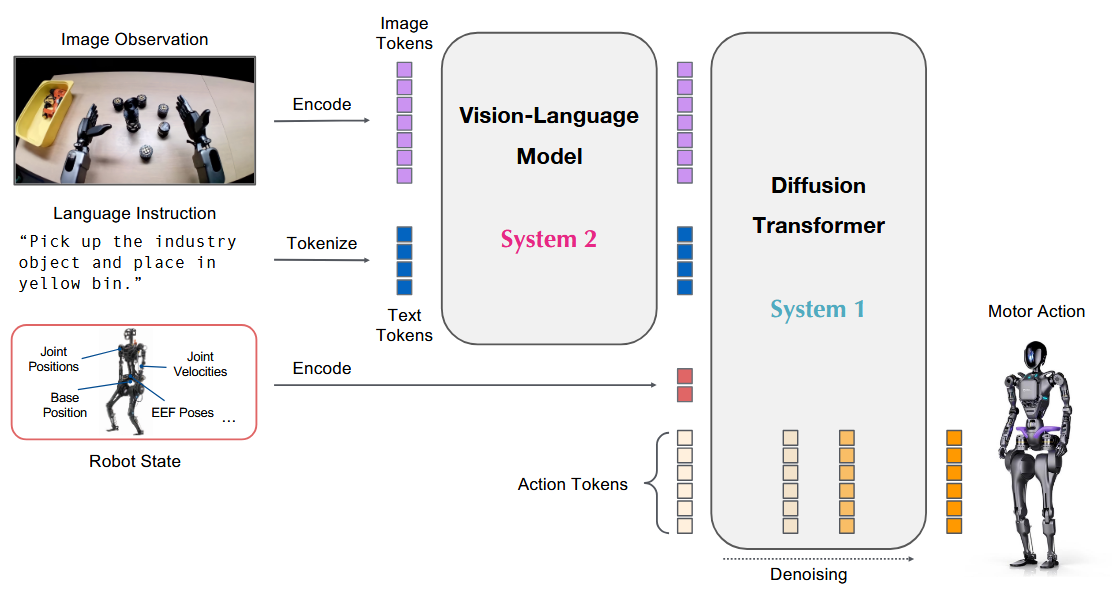
Modern large vision-language-action models consist of a VLM “head,” taking in images and language, and a diffusion transformer (-ish) model to predict action snippets. And the important thing is that they can train on lots of different data sources: webscale image-language data, human task data, AI generated videos.
So, fundamentally, we are seeing the core ideas from ALOHA and Diffusion Policy — as far as how to predict actions correctly — turn up here, with addition of a semi-modular structure that lets them benefit from training on wildly disparate data sources. And as they train on tons of different sources, often co-training on web data or, in GR00T’s case, on object prediction. This gives them an unparalleled ability to generalize, as has been demonstrated in many different papers as well as this fun X thread by Igor Kulakov (link).
Final Thoughts

All of this honestly represents a pretty dramatic shift in my thinking. I used to very much be on the planning/modular methods side. I still do believe our end-to-end, data-driven future will be modular - VLAs are all modular, after a fashion - but I think that they will be, increasingly, modules that are trained end-to-end and with specialized components for different tasks determined by data availability, not by top-down design.
We will run out of teleop data eventually; this isn’t a “learning from demonstration is the only way” kind of story. I have not yet seen that particular light. Having humans collect data will always have its limits; I expect that eventually we’ll see manipulation policies learned and improved via autonomous data collection. Cobot founder Brad Porter mentioned this in a recent blog post; talking about how their robots were starting to “learn from play,” i.e. reinforcement learning.
And one last note: all this does not mean it’ll be easy. It’s not easy for the LLM companies: Crystal of Moonshot AI, after her company’s stunning release of the LLM Kimi K2, said that the data work was the most grueling part of what they did. Scaling laws don’t mean any data is good; you still need algorithms and processes to find, generate, and curate the right data. So even if data does “solve” robotics, there’s still a lot of work to be done.
Learn More:
DexWild on RoboPapers: watch or listen to our discussion with the authors.