
Paper Notes: Fine-Tuning Large Vision-Language Models as Decision-Making Agents via Reinforcement Learning
How do we train AI agents that can perform tasks from vision and language?

I have a huge backlog of papers to read. Let’s go through some of them together, starting with this one: Fine-Tuning Large Vision-Language Models as Decision-Making Agents via Reinforcement Learning (RL4VLM) [1].
Large vision-language models need to function as agents capable of interacting with their world to provide value. We want AI agents that can, say, book a flight for us, or navigate the DMV portal, or whatever. This is the premise that has launched a million YCombinator startups. But the data to build these agents doesn’t, as a rule, exist.

The Problem
AI Agents need to be able to interact with the world. While it’s possible to do this mostly via text, there’s a ton of information that will necessarily be missing if we do so. Instead, we want agents who can take actions in response to images.
Language data online is generally not trained to take sequential actions; many assessments of language models (like the wonderful LMSYS chatbot arena) are highly biased towards fewer “steps,” generating big blocks of output without getting feedback from the “world.” Of course in the case of chatbot arena, that "world” is just a human interacting with the AI. In our case, the would could be anything, including something approximating the actual world — see below.

So, to summarize: in this paper, the authors will fine tune a large vision-language model to perform sequential actions in response to visual inputs [1]. I’ll go into what that model is, and how they will tune it next.
The Model
The authors fine tune a variant of LLaVa. LLaVa is from the very important paper Visual Instruction Tuning by Liu et al. [2], so we should probably go over what this model actually is.
LLaVa is Large Language and Visual Assistant, an open-source fine tune of an LLM (Vicuna - based on Meta’s Llama 2), together with CLIP ViT-large. For more on CLIP, you can see see my post on visual feature learning.

At a high level, we’re going to prompt GPT4 to generate a big dataset of image-language data. Then, we’re going to tune an adapter between our CLIP visual encoder and our large language model.

The idea is quite simple, as all the best ideas are: take your pretrained CLIP visual encoder (which already captures language quite well), and learn a projection from visual features to the “space” of the language tokens. Everything else can stay frozen!
This gives us a model architecture — LLaVa 1.5 — that achieves SOTA on 11 benchmarks, trains in about a day, and can perform vision + language actions (from the project page). It can generalize to unseen image prompts and perform similarly to GPT4 on some examples.
LLaVa is also used in a lot of my favorite works of the last couple years, including things like ConceptGraphs [3], and it’s also been extended to video and multi-image settings [4]. It’s a great foundation for playing around with vision-language agents.
The Method
So, we have a vision-language model - LLaVa - that we can use to make decisions. However, it’s still not perfect. It makes mistakes, and it’s trained on this synthetic data which is kind of a mess, and which doesn’t handle complex multi-step actions. How can we make it better?
Well, as always, the problem is data. There is not a lot of good data for this task in the world, so, as in many cases where we have a good simulator and a clear task, we're going to use reinforcement learning.*
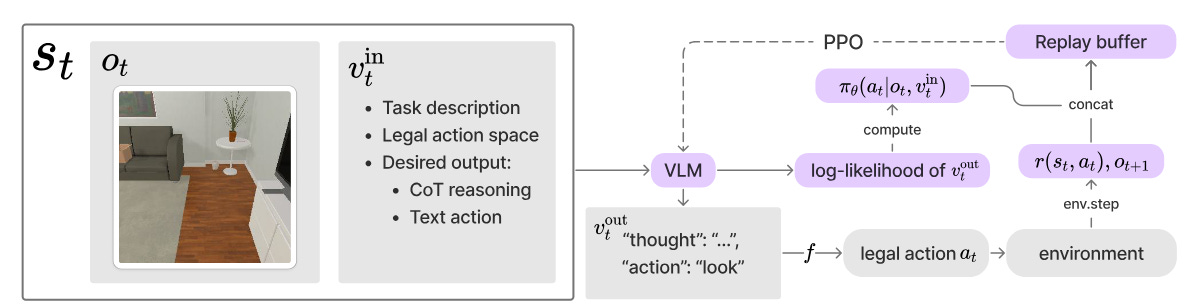
Our RL agent is going to be trained using Proximal Policy Optimization, which is a very powerful RL algorithm used for things like playing DOTA2 [5].
At a high level:
Give a language command to the agent, based on its environment, which prompts the agent to do chain-of-thought reasoning as well as tells it which actions are valid
Also provide an observation image, demonstrating what the agent can see.

Above you can see an example of how this is prompted. This is a fairly generic prompt; it’s easy to see how it might be adapted to different tasks. There’s a post-processing function which attempts to look up the action a in the set of legal actions; if it’s not found, the agent takes a random action in order to facilitate RL training.
*As an aside: for another cool example using Generative AI and RL, you can look at Google Deepmind’s work on simulating the game Doom. In RL4VLM, the goal was to learn a policy; for the Doom work, the policy was incidental, and was just a means of collecting data.
Takeaways

Well, we finally have an AI that can play Blackjack with you from pixels, just like a human might.
The authors show that chain-of-thought reasoning remains extremely important, especially for arithmetic tasks (e.g. Blackjack).

Their fine-tuned models also end up being a lot better than GPT-4V on the tasks. On the one hand, this might not seem too surprising - GPT wasn’t trained on Alfworld - but GPT is an incredibly strong baseline and it often feels like a lot of papers these days just end up showing how good it is already! Crushing it with a 7B model on your specific task is very cool.
Weaknesses: it seems like it will be very susceptible to tuning, and of course whatever task you want to use it for needs to be simulatable and it’s not clear how often this will be the case. Probably difficult for many practitioners to apply.
Verdict: a really interesting paper that COULD be very impactful, as it discusses how to build AI agents that can interact with the world, and how to automatically collect the data you need to tune them to succeed at those tasks. Cool work.
References
[1] Zhai, Y., Bai, H., Lin, Z., Pan, J., Tong, S., Zhou, Y., ... & Levine, S. (2024). Fine-Tuning Large Vision-Language Models as Decision-Making Agents via Reinforcement Learning. arXiv preprint arXiv:2405.10292.
[2] Liu, H., Li, C., Wu, Q., & Lee, Y. J. (2024). Visual instruction tuning. Advances in neural information processing systems, 36.
[3] Gu, Q., Kuwajerwala, A., Morin, S., Jatavallabhula, K. M., Sen, B., Agarwal, A., ... & Paull, L. (2024, May). Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning. In 2024 IEEE International Conference on Robotics and Automation (ICRA) (pp. 5021-5028). IEEE.
[4] Li, B., Zhang, Y., Guo, D., Zhang, R., Li, F., Zhang, H., ... & Li, C. (2024). LLaVA-OneVision: Easy Visual Task Transfer. arXiv preprint arXiv:2408.03326.
[5] Berner, C., Brockman, G., Chan, B., Cheung, V., Dębiak, P., Dennison, C., ... & Zhang, S. (2019). Dota 2 with large scale deep reinforcement learning. arXiv preprint arXiv:1912.06680.
Learn More
ArXiV: https://arxiv.org/pdf/2405.10292
Project site: https://rl4vlm.github.io/