
Paper notes: Improving Vision-Language-Action Model with Online Reinforcement Learning

Many vision-language-action models really don’t work that well. Even as this changes with the open-source release of Pi Zero, there’s a place for improving on these large action models further. Enter this new paper, which uses reinforcement learning to improve vision-language models.

Just a note: I initially saw this when it was shared by Chong Zhang on Twitter/X. He’s worth a follow if you’re even remotely interested in AI and robotics.
Problem Statement
Fundamentally, learning from demonstration (LfD) — also called imitation learning, or behavior cloning — is limited by the quality of demonstration data available. Sometimes that data isn’t high quality. Other times, like for reasoning models, the data just does not exist.

Now, robotics has a mixture of both problems. Data is generally hard to collect — it’s expensive, since you actually are paying for every single piece of it, you can’t scrape the web like OpenAI or have drivers pay you for the privilege since they also get a car out of it, like Tesla — but also, even expert teleoperation can only take you so far.
Reinforcement learning generally doesn’t work on hard problems if you “cold start” it — we see this again and again. So what we do is RL on top of something already trained on what data we have available (well-explored for language models in blog posts like this one from Nathan Lambert). The authors themselves draw this parallel:
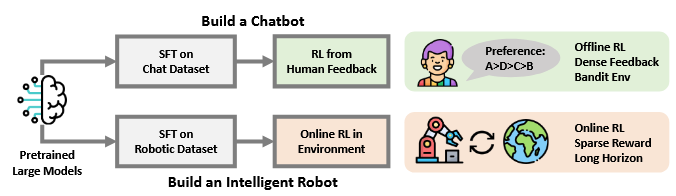
So, the authors want to try to do RL on top of a pretrained vision-language model. Fine. What’s so hard about that?
Well, it turns out that this is very unstable, so they propose an iterative approach: iRe-VLA, which iterates between supervised fine tuning and reinforcement learning.
(Here, I really want to draw a parallel to this wonderful post by Andrej Karpathy: even in language models, we often can’t just run endless RL iterations, though it’s sort of for different reasons. Supervised fine tuning remains a key part of the recipe, right up until the end — yes, even for Deepseek).

The Method

The authors start with a large vision-language model, pretrained on the usual data. They use BLIP-2 3B, which is certainly on the smaller side, but should be good enough for robotics (I did Stretch AI with similarly sized Qwen models).
Then they go through a few stages:
Supervised fine-tuning on a large expert dataset, consisting of high-quality robot data. This gives them a good starting point.
Freeze the VLM parameters (yellow, in (a) above) and only train the action parameters. Train only the action head via reinforcement learning. This has the advantage of being far fewer parameters, and thus manageable for the reinforcement learning algorithm, but unfortunately the whole VLM stack is not optimized, which means it’s still bounded in performance. So we add one more step…
Do supervised training of the whole model, on expert data and data collected online during the reinforcement learning process above.
This pipeline should avoid forgetting, generalize and improve performance in new environments, and is more stable than directly reinforcement learning all of the weights all the time. Freezing the weights during RL is extremely important here:

You can see that in many of the reinforcement learning tasks, performance with an unfrozen VLM backbone craters or just fails to improve. This is a nice result, and something to take away if you’re trying to train a model like this.
Experiments
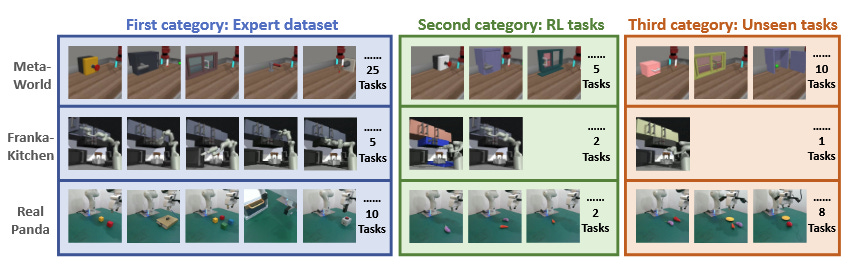
The data is a mixture of simulated and real-world problems. They show strong performance compared to baseliens (of course; this is a scientific paper after all).

There are also a good number of real world experiments, again showing the same trend: notably better results, especially on unseen tasks. It looks like all the real-world generalization is task generalization, not scene generalization, but that’s pretty normal.
Final Notes
The key takeaway for me was: you can do RL with very large models, and you should do it by freezing the VLM, then co-training on the resulting dataset to improve overall performance. Nice paper, clear message, looking forward to seeing how well it works on more complex mobile manipulation tasks, where generalization is harder and more important.
Find the paper here: ArXiV
References
Guo, Y., Zhang, J., Chen, X., Ji, X., Wang, Y. J., Hu, Y., & Chen, J. (2025). Improving Vision-Language-Action Model with Online Reinforcement Learning. arXiv preprint arXiv:2501.16664.