
The Limits of Reinforcement Learning
Reinforcement learning has been posited as a solution to the looming "data wall," but it isn't. That doesn't mean it's not a powerful tool.


Over the last year or so, we’ve seen increasing concerns about the fact that we’re, well, running out of data to train on, something occasionally referred to as the “data wall.” One suggested solution to this is that AI systems can “generate their own data” by exploration and self-improve. The concept is perhaps best illustrated by Deepseek R1, which famously was partially trained via reinforcement learning (RL) on math and coding problems to build its impressive reasoning capabilities.

And at the same time, we’ve seen truly incredible videos from, companies like Unitree and EngineAI, showing robots trained to do karate or dancing using reinforcement learning. It’s become the ideal way to train robots to walk, to the point that even famously old-school Boston Dynamics is doing it.
But this is a post about why reinforcement learning doesn’t work. Because RL, while amazing, is a very specific tool for specific use cases, and not a panacea — let me explain why.
But first, if you’re interested in this kind of post, please subscribe:
Why do we need reinforcement learning at all?
The problem basically goes like this:
AI agents need data to train on, combining both actions (what to do) and observations (what the agent sees).
In addition, they need increasingly more data in order to see a linear increase in capabilities — potentially more than we can pull from the internet. And that’s not to mention robotics, for which this data does not exist at all!
Getting complete sequences of observations and actions to train on is difficult; why not just the model explore and generate its own data?
The study of how to do this — to have an intelligent agent learn how to best act in an environment in order to maximize some objective function — is called reinforcement learning (RL).

In the diagram above, you can see a simplified version of the problem. Our agent chooses actions, which affect the environment. It then receives state observations and a reward signal. This reward is what lets the agent differentiate good from bad; it’s really important when determining what problems are suitable for RL.
Note: the diagram, and a lot of the literature, will refer to the inputs our agent receives as “state.” I’ll be referring to them as observations, because we’re really dealing with a partially-observable Markov Devision Process in any realistic use-case for RL, but that really doesn’t affect anything to follow.
Using Reinforcement Learning
To set up a reinforcement learning problem, we define all of these different aspects:
An observation space — sensor measurements our agent will use, or just “text inputs” as per Deepseek R1
A reward signal — something which determines how good a given state/action pair is, which can be very complicated
An environment to evaluate all of this in.
Take, for example, the video above, from my OVMM project. The goal here was to build a generalist robot agent, deployable on a low-cost home robot exploring complex, previously-unseen environments.
This is where we hit our first problem: observations at training time need to look like observations at test time. The reinforcement learning agent is going to continually update itself, getting better and better and exploiting any details of the environment that it can find to maximize its expected reward; it will, in short, overfit itself to train as much as possible. And we’re doing RL in simulation, and the simulation renderer is just not going to look like the real world environment, above. In fact, it looks like this:
We imagine access to robot pose (via a SLAM system, like the one provided by Nav2), as well as robot joint states and camera inputs. But since the simulation doesn’t look like the real world, we can’t actually use raw RGB inputs: instead we use depth (with some augmentation), which looks more or less the same between sim and real, and segmentation masks, 2d binary images indicating which pixels belong to which object — because these can be generated from an object detector.
This brings us to limitation 1: your observation space at training time needs to look the same as at deployment time. Without all of these hacks, this system just wouldn’t work. But this is a well-studied and solveable problem, so let’s move on.
The observations, then, are segmentation maps, depth images, robot joint states, and robot base poses (imagined to be outputs from a SLAM system). The actions are the robot’s base and arm position. What else do we need?
The Reward Function
Most robotics work uses what’s called a dense reward function, meaning that it provides an informative signal at every time step.
We’ll start with OVMM as an example. The reward for object search looks like this, from the paper:

With an additional slack reward, a penalty applied to each action to encourage it to get its job done in a reasonable timeframe. The value and structure of this reward function is extremely important because it has to encourage the agent to explore in good directions.
In addition, the state and action spaces here need to be close enough to the real world that we can actually employ them on the real robot — this meant that, for this project, we didn’t actually use RGB input in simulation, just segmentation masks. Something we also were able to use for sim-to-real RL for nonprehensile manipulation:
In this case, from the HACMan project, the input is a point cloud and a segmentation mask - a 2d object detection, which we used to tell the policy which parts of the image were the object we wanted to manipulate.
Now, those are sim-to-real perception papers. The same, though, applies to a lot of the cool robot dancing videos that have been coming out; their state space is the space of robot joint state measurements, actions are joint positions or velocities. Again, we can get a strong, locally useful reward signal.
The reason for this is because for robotics policies, we are generally starting from a blank slate. The reward function needs to guide exploration.
But What About Deepseek?
But wait! Deepseek, unlike all these robotics works, did not use a dense reward function. It’s reward was very simple:
For math problems, verify correctness
For coding problems, run a compiler
Check formatting: make sure that <think></think> tags are in the correct place in the outputs.
Compare that to some of the crazy shit you see in robotics papers:
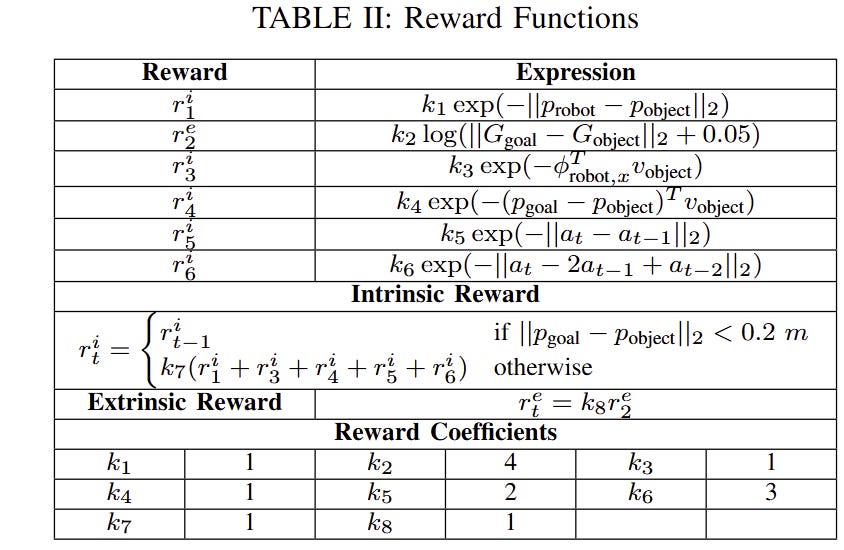
How is this possible? Well, two things:
Deepseek spent a lot more time and money on this. Their final training run was estimated to cost $5-6 million, which is quite a bit more than anyone is going to spent on robotics training (for now). More time and money means more samples, which means more potential for exploration.
But, much more importantly, Deepseek has a powerful base model to build on. Basically, Deepseek does not need a dense reward function because it’s already close to solving the problem.
This is because a lot of this complexity comes from the need for the reward function to do double duty, guiding exploration to good solutions in addition to distinguishing good solutions from bad ones.
Exploration
Exploration is the fundamental problem reinforcement learning needs to solve. RL agents need to sample useful things, and some less useful things, and from the differences between these samples, be able to determine what actions are good and which are not.
Ideally, we would often rely on a sparse reward function, similar to what Deepseek uses: a simple -1 or 0 or 1 for whether a particular solution is bad or good. But then our agent can’t tell which directions are worth exploring! So we add layer upon layer of complexity to guide the solution in the right direction and help the algorithm differentiate good from slightly better.
This is not a huge issue for the Deepseeks and OpenAI-o1s of the world, because they have a base model which can perform adequately well:

Deepseek v3, their base model, actually performs fine on coding (58.7 on codeforces) and quite well on math (90.2 on Math-500, pass@1). If you increased all of these to pass@5 or pass@500, I think we can all imagine how accuracy would go up quite a bit. That’s important: the base model can generate the right answer, we just need to find it.
So, since it can generate the right answer, and we can easily verify math and coding accuracy at training time, so we get exactly what is necessary for reinforcement learning to succeed: a mix of good and bad answers, with different associated rewards, which gives us a strong signal that can be used to update the policy.

The closest robotics analogue I can think of is the MT-Opt line of work from Google Robotics. This was a project which used their “arm farm,” a row of robots doing picking tasks. These robots could succeed at simple versions of the task as much as 30% of the time! That means you don’t need the crazy complexity of rewards above, and made it practical to train reinforcement learning skills for manipulation in the real world.
The Implications for Reasoning
We can summarize the constraints as follows. We need:
Input observations that capture the task and look the same at training vs test time
A way of validating that the learning agent has achieved good solutions
Some solution to the exploration problem — either a locally informative reward function, or a good enough initial policy that we’re already solving the problem some of the time
All of this has some serious implications for whether or not reinforcement learning will be able to learn complex reasoning skills, something that we’re increasingly seeing in the literature [1, 2].
The first problem is that not all reasoning problems are verifiable. At least, not programmatically.

Abstract reasoning problems can only be verified by a human expert; thus, Deepseek ends up using a mixture of supervised fine tuning and learned reward models to get generalized reasoning back.
But generalized reward models don’t yet exist, and learned reward functions are highly exploitable by clever reinforcement learning algorithms. Your reinforcement learner will exploit any loophole it can find in your reward function — it’s a big reason RLHF generally can only be run for a short period of time, as noted by Andrej Karpathy in this discussion on Twitter/X.
Could we have an LLM act as its own teacher? Perhaps, but this seems extraordinarily expensive, and I think it would run into similar problems — if it’s judging itself, what’s to keep the model aligned?

But that’s not the only problem, as we see in [2]. Because in this regime, our exploration is still limited to the solutions generated by the base model! In fact, they actually ran the experiment I mentioned above, and tried various LLMs with different pass@k thresholds for increasingly larger K’s. The base models always surpass the RL models. The knowledge is there already, the RL is just bringing it out and making it useful to us.
So When Can I Use RL?
Reinforcement learning is a powerful tool. Right now, though, it’s best used when:
You have a verifiable problem: math, coding, robot grasping
You have a way to generate a ton of data in this domain, but can’t necessarily generate optimal or even good data
The exploration problem is locally tractable, so that when generating this bad data, you will still make some progress
This problem is clearly bounded and is well-posed— think “math olympiad questions” or “walking robot”, not “general-purpose home robot”
Core questions of data efficiency, exploration, and scalability still remain, but it’s still one of the most exciting places to be working right now. If you have any thoughts — or disagree — please leave a comment, and if you want more like this, hit subscribe.
References
[1] Zhao, R., Meterez, A., Kakade, S., Pehlevan, C., Jelassi, S., & Malach, E. (2025). Echo chamber: Rl post-training amplifies behaviors learned in pretraining. arXiv preprint arXiv:2504.07912.
[2] Yue, Y., Chen, Z., Lu, R., Zhao, A., Wang, Z., Song, S., & Huang, G. (2025). Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?. arXiv preprint arXiv:2504.13837
[3] Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., ... & He, Y. (2025). Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948.
Seems like this could be missing RLHF as an example of where we can use RL, which already points to how soft verifiers can be mixed in with verifiable. I think the appetite for RL is now higher on the capabilities side, so there's line for optimism.
Of course, I agree with all the limitations when it comes to applying robotics/rl classic like ideas.
Amazing blog! I’d love to see a part two that explores the tools we can use to address these RL constraints. No RL algorithm can fully overcome them yet, but as you showed, we have ways to mitigate them-especially in robotics. 🦾
Of the three main constraints, input observation is the toughest-especially with RGB images and generalization. Right now, simulations have to be almost 1:1 with the real world. The main solution seems to be adding more modalities or learning better latent representations.
For validation, I’m really curious to see what people come up with using VLMs as a replacement for RLHF. There’s a lot of potential there.
Exploration is still tricky, but starting with a policy trained via supervised learning or offline RL can help bootstrap the process.
But the biggest challenge, IMO, is that the problem always has to be clearly bounded. RL just can’t handle long-horizon tasks without a sophisticated framework. We definitely need a breakthrough in hierarchical RL!