
What are the data scaling laws for imitation learning in robotics?
Diverse, quality data is all you need.

There are a lot of expensive parts to running an AI-in-robotics company. Data is expensive and time-consuming to collect. Compute is expensive. Infrastructure needs to be build out. To make big investments in learning, we want to understand the payoff. Fortunately, the AI + robotics community is starting to get a picture.

Recently, Fanqi Lin et al. released a paper called “Data Scaling Laws in Imitation Learning for Robotic Manipulation,” wherein they look at answering the question: “can appropriate data scaling produce manipulation policies that work for any robot, in any environment?”

For their hard work, they actually won best paper at a CoRL workshop (CoRL is the Conference on Robot Learning; it’s the trendy place to be if you’re a robotics researcher).
But first if you like this kind of thing please subscribe!
What are Scaling Laws, Anyway?
There are three key resources for training a neural network:
Parameter count (how big your model can be)
Number of training tokens (how much training data you have)
Compute budget (how many GPU hours can you burn)
We expect that these all follow a power law relationship with the underlying loss, i.e. that with more data, parameters, and compute, we’ll see better performance on the objective.

And this is, in fact, what we see! There’s an exponential relationship between things like compute and training tokens, and how quickly models reach good performance.

Google Deepmind researchers released the paper Training Compute-Optimal Large Language Models, which despite not having a crazy citation count is an incredibly important and influential paper stating that current generation models (this was GPT3 era) were significantly under-trained.
These aren’t really “laws” in my opinion; they’re more just rules-of-thumb, saying that for every increase in model size, the number of training tokens should be scaled equally (so if you double the parameter count, you should also double the amount of training data). For more on scaling laws, you can check out this blog post from Nathan Lambert.
Fast forward to today, when everyone wants to be able to train models on their robots, but we do not yet have large datasets. Not only that, many of these companies don’t yet have huge teams or infrastructure to train large models. Figuring out what and in what order to build things out, to spend limited money and time, is important.
There’s been some similar work in scaling laws for single-agent video games, but very little on the messy problem of real-world robotics. Partly, the issue is one of data, which mostly doesn’t yet exist for robotics.
Instead, in robotics, where we want generalizable policies and none of the data even exists yet, there are still more questions to answer.
Scaling Laws in Robotics
The problem is that in robotics we specifically care a lot more about generalization: robots will need to operate on a wide range of environments, objects, and lighting conditions, and the data doesn’t really exist for training models on these yet. Even the very largest robotics datasets like Open X Embodiment are actually really tiny in the scheme of things.
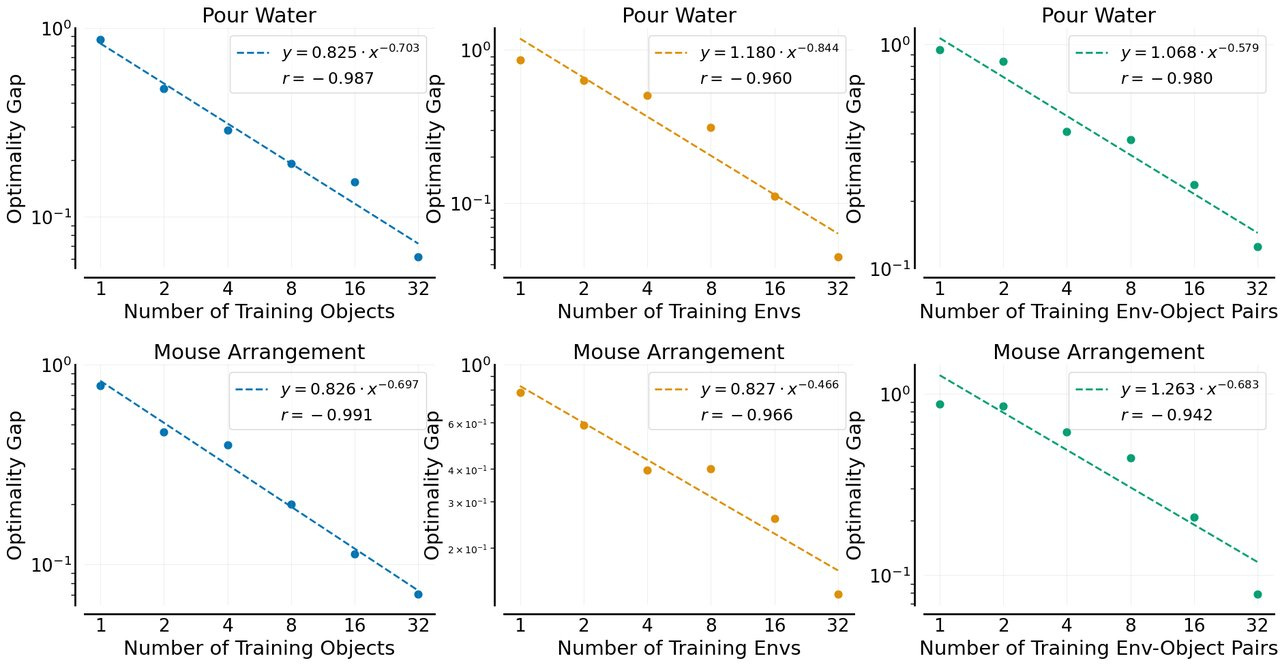
In the paper Data Scaling Laws in Imitation Learning for Robotic Manipulation, the authors collected 120 demonstrations per object for 32 different objects, for each of two different manipulation tasks: pour water and mouse arrangement. Separately, they also train across 32 different training environments; finally, they have one case where object and environment are varied simultaneously (still 32 pairs). All have roughly 3,820 demonstrations at the end (again, minus those demonstrations removed due to SLAM filtering).

The most important result is this: when collecting the maximum number of demonstrations, we see that more diversity is clearly better.
Does this hold up across other works? Well, there’s some earlier work in Robot Utility Models (I’m an author!) which takes an extremely similar approach.
In Robot Utility Models, we collected a large number of demonstration videos — 1000 examples in 40 environments — using a tool called “the Stick." The lead author, Haritheja, even demonstrated it live at a conference on completely new furniture. This one really does 100% actually work - I’ve even used it in my house.
Unlike the first paper, Robot Utility Models performs five tasks:
Door opening (seen in the video above)
Drawer opening (similar, but pulling directly back)
Reorientation (pick up a bottle and put it upright)
Tissue pickup (pull a tissue out of a box)
Bag pickup (pickup a bag from a flat surface
Getting a 90% success rate on totally unseen environments. The trick is the Stick allows for collecting a really broad diversity of data very quickly.
To demonstrate the importance of this, the RUM paper contains this experiment:

This compares training, given an equal amount of total data, on a large number of environments vs a small number with a lot of data. Again we see the same pattern: data diversity counts for a lot!
Lessons
We’re starting to see a consensus that:
Ability to generalize for a particular task is going to scale as a power law proportionate to the number of environments you’ve seen
There are clear diminishing returns to data from the same environment. Both papers observed this. It doesn’t matter if you have millions of examples on clean lab benches, you’ll get no closer to general robot intelligence.
Dataset diversity is crucial: collecting across many different objects, environments, and lighting conditions (a minimum of 40 distinct environments, according to RUM!)
Dataset diversity has huge implications. It means that you need ways of easily collecting very interesting data - Robot Utility Models uses the Stick, scaling laws uses UMI. This lets you just walk around and collect examples, though even this still isn’t trivial! If you want to do this with a robot, it will need to be portable and probably human-safe-ish (like Stretch or the 1x Neo, or maybe the Booster T1 - which is quite lightweight).
If you like this post, please share it:
And if you really like it please subscribe:
I plan to write up conference posts on IROS and CoRL next (hopefully very soon!), and a post on domain randomization — the simulation answer to this data diversity problem.
Learn More
[1] Etukuru, H., Naka, N., Hu, Z., Lee, S., Mehu, J., Edsinger, A., ... & Shafiullah, N. M. M. (2024). Robot utility models: General policies for zero-shot deployment in new environments. arXiv preprint arXiv:2409.05865. Website
[2] Lin, F., Hu, Y., Sheng, P., Wen, C., You, J., & Gao, Y. (2024). Data Scaling Laws in Imitation Learning for Robotic Manipulation. arXiv preprint arXiv:2410.18647. Website