
What does the world representation for home robots look like?
Capturing semantic and spatial information is a key part of how we can build

For them to be useful assistants, robots must be able to understand their environment. Vision-language models like GPT-4o are actually great at understanding their environments, at least from a single image; unfortunately, they’re still not amazing at understanding the relationships between different objects and understanding images over time.
Building rich, open-vocabulary world representations allows us to execute complex multi-step queries, have robots that can answer questions, clean up a room, or fetch a cup of coffee. You can’t just rely on end-to-end policies for this — not yet — because we simply don’t have the data for totally unstructured approaches yet.
But this is the kind of stuff we can build already:
In this video from ConceptGraphs [1], the robot is given an open-vocabulary query, something that it was not trained on, and is able to move around in its environment to satisfy that query even though it fails initially, using its world representation.
What does that representation look like?
There are a few alternative approaches that are useful to consider:
Directly use a large multimodal model like GPT4. This can be as simple as throwing a bunch of individual image frames at a GPT-style large VLM, which is what we did in OpenEQA [2]. You can improve on this with Retrieval-Augmented Generation (example [5], example [6]).
Use a set of learned, spatially-organized features to create a map which can then be used for navigation and queries. This is the approach taken by, for example, CLIP-Fields [3], Ok-Robot [4], and ConceptFusion [7].
Use an open-vocabulary scene graph like ConceptGraphs [1]
I’ll go through some of the advantages and disadvantages of each one. In future posts I intend to go into these approaches in more detail.
Large Multi-Modal Models
The most natural way to solve the problem is to… not bother solving it at all. Just go ahead and throw a bunch of individual frames at your favorite large vision language model!
Models like GPT-4o can take in more and more frames of video; Gemini is particularly good at this right now, although of course which model is the best is always changing. But we’ve seen for quite a while that these models are improving; GPT-4o was a noticeable improvement over GPT-4V on OpenEQA, for example.
Most OpenEQA problems can be answered from just a couple frames, though. For problems requiring handling of really long video sequences, we might still see poor performance. For this, we can turn to techniques like Retrieval-Augmented Generation, or RAG, which has been exploding recently, and has the advantage of being extremely simple to use. In short, RAG works by looking up relevant examples from a much larger dataset as a part of answering a question.

We’ve recently seen this applied to robotics into concurrent works [5,6]: Remember from NVIDIA [6] and Embodied RAG from CMU [6]. Both models rely on video captioners to create a large dataset that can be queried; this likely limits how well they can work on specific, granular, object-level queries (like you might use for a mobile manipulator). In the future, though, we might expect to see this change with better video models, or with approaches that directly save visual features.
Spatially-Organized Features
Speaking of visual features, there’s another family of approaches which more-or-less directly outputs these into 3D space, exemplified by work like CLIP Fields [1], Lerf [7], Langsplat [8], and more.
OK Robot is probably the simplest of these approaches, directly projecting semantic features into 3d space, and it’s also the one that I think is most heavily proven for robotics: it’s been tested on 171+ different pick-and-place tasks across 10+ homes (including mine).
Weaknesses: these lack any real notion of “objectness,” meaning that while it can answer granular queries, they aren’t as capable of long-term planning. They’re also often slow, requiring an arduous preprocessing step to get a world map “ready” for robots to use it.
Scene Graphs

Scene graphs have been around for a long time, but are recently having a bit of a resurgence thanks to works like ConceptGraphs [1] (which prompted this post, despite being from last year). Another fantastic example is HOV-SG [8], which uses Segment Anything and CLIP to construct queryable open-vocabulary maps so that robots can execute complex multi-step queries.
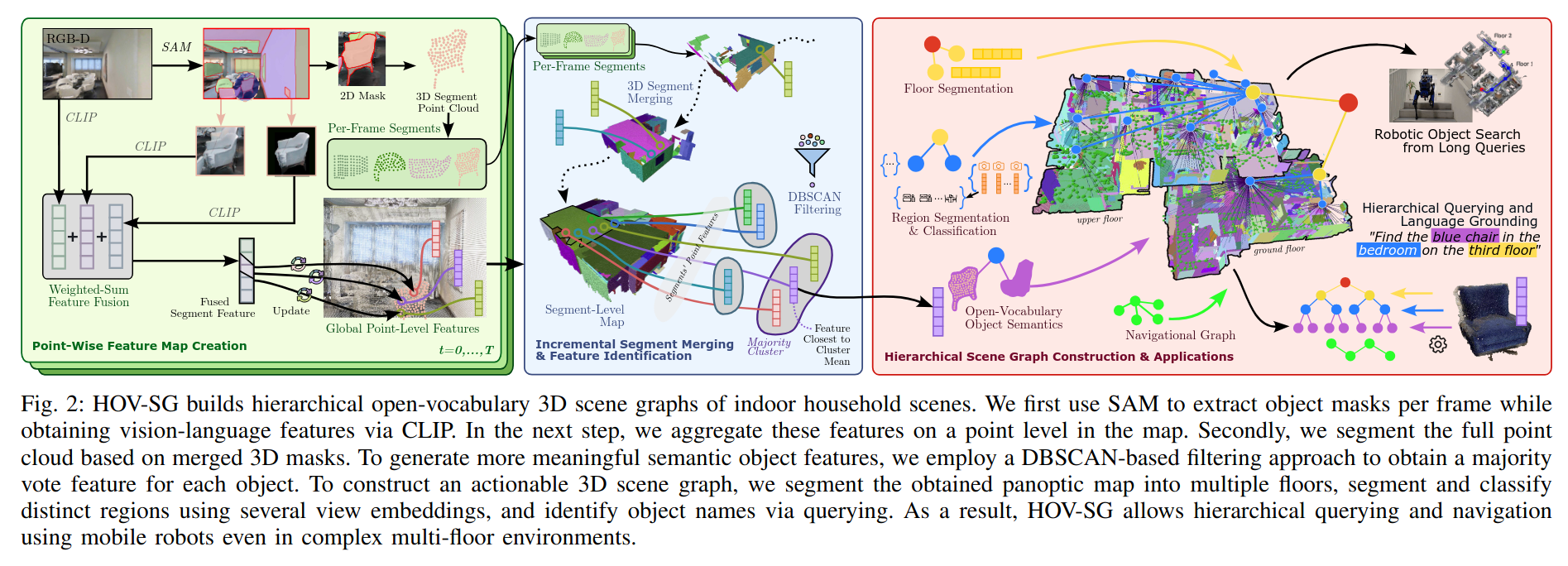
Instead of being relatively unstructured text, like RAG, these scene graphs capture object-specific information, which means they’re more capable of multi-step planning and reasoning (check out the ConceptGraphs website for some cool examples). These are very complex systems — see above! — and they’re probably still not quite ready for widespread deployment, but they use this extra structure to address a lot of the gaps of the above. The weakness is they have a lot of hyperparameters to tune, and are still often slow and “offline.”
Conclusions
Some commonalities:
Basically everything that “works” is using SLAM, building a map of some kind, recording positions, and saving open-vocabulary features using large vision-language models. You’re not getting away from building a classic robotics stack, if you want a generally-useful robot — at least not yet.
GPT-4o is really widely used. It’s fast, it’s cheap — you might as well start there. Edge models are too slow to iterate on.
Manipulation is still very rare, and replanning is almost nonexistent. There are some huge gaps in the current literature that need to be addressed.
If you want to learn more, check out some of these references; you can also look up the awesome robots 3d github repository.
I do think in the future, we’ll train models to construct this internal representation, and that representation will look more like multi-modal RAG, probably with some kind of spatially-informed hierarchy to aid retrieval. But we have a long way to go before we get there.
References
[1] Gu, Q., Kuwajerwala, A., Morin, S., Jatavallabhula, K. M., Sen, B., Agarwal, A., ... & Paull, L. (2024, May). Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning. In 2024 IEEE International Conference on Robotics and Automation (ICRA) (pp. 5021-5028). IEEE.
[2] Majumdar, A., Ajay, A., Zhang, X., Putta, P., Yenamandra, S., Henaff, M., ... & Rajeswaran, A. (2024). Openeqa: Embodied question answering in the era of foundation models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 16488-16498).
[3] Shafiullah, N. M. M., Paxton, C., Pinto, L., Chintala, S., & Szlam, A. (2022). Clip-fields: Weakly supervised semantic fields for robotic memory. arXiv preprint arXiv:2210.05663.
[4] Liu, P., Orru, Y., Paxton, C., Shafiullah, N. M. M., & Pinto, L. (2024). Ok-robot: What really matters in integrating open-knowledge models for robotics. arXiv preprint arXiv:2401.12202.
[5] Anwar, A., Welsh, J., Biswas, J., Pouya, S., & Chang, Y. (2024). ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation. arXiv preprint arXiv:2409.13682.
[6] Xie, Q., Min, S. Y., Zhang, T., Bajaj, A., Salakhutdinov, R., Johnson-Roberson, M., & Bisk, Y. (2024). Embodied-RAG: General non-parametric Embodied Memory for Retrieval and Generation. arXiv preprint arXiv:2409.18313.
[7] Kerr, J., Kim, C. M., Goldberg, K., Kanazawa, A., & Tancik, M. (2023). Lerf: Language embedded radiance fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 19729-19739).
[8] Werby, A., Huang, C., Büchner, M., Valada, A., & Burgard, W. (2024, March). Hierarchical Open-Vocabulary 3D Scene Graphs for Language-Grounded Robot Navigation. In First Workshop on Vision-Language Models for Navigation and Manipulation at ICRA 2024.