
Learning Robotic Manipulation from Simulations
A comparison of a few recent works on sim-to-real robot manipulation that I liked

A big part of scaling robot learning to solve real-world problems is that we somehow need to get enough diverse, high-quality data to train our robots to perform useful things. GPT and its fellow large language models were bootstrapped and proved out on a massive dataset of real-world language data (datasets like The Pile). Unfortunately, despite our best efforts, similarly massive datasets don’t really exist for robotics — so, in our unending pursuit of high-quality, useful data, we turn to simulation.
Here, I’m going to write about a couple works that I’ve seen lately which talk about how to train perception-driven manipulation policies in simulation, in such a way that they’re useful in the real world.
DextraH-RGB, from NVIDIA [1]
Sim-and-Real Co-Training: A Simple Recipe for Vision-Based Robotic Manipulation, also from NVIDIA — specifically the GEAR lab [2]
Sim-to-Real Reinforcement Learning for Vision-Based Dexterous Manipulation on Humanoids, another GEAR lab paper [3]
Local Policies Enable Zero-shot Long-Horizon Manipulation, from CMU (although the lead author is now at Tesla) [4]
And, yeah, that’s a lot of papers from NVIDIA. NVIDIA is the leader in this line of work; they’ve long championed their Omniverse simulator, which has received considerable uptake across different research groups. They’re also admirably open and have a very talented set of researchers. And, of course, I might be a bit biased here - I used to work for NVIDIA and I’m still quite fond of the crew.
But before we continue, a short note on what we are not covering: anything to do with locomotion, basically, and anything to do with navigation. Last year, we saw some particularly impressive sim-to-real works in this space. One I really liked was Poliformer [5] from the Allen Institute for Artificial Intelligence won the Outstanding Paper Award at the prestigious Conference on Robot Learning in Munich, Germany. I’ve also written a broad overview of this all before, which you can check out below.
A Closer Look at DextrAH-RGB: Grasping with Stereo Vision from Sim to Real
First, let’s look at learning a single, highly general skill. In DextraAH-RGB (henceforth just Dextra), the authors learn a single general-purpose grasping policy in simulation. This is an extension of DextrA-G [6], a similar work which used a structured light RGB-D camera — a powerful but very limiting piece of technology.
Dextra goes through a couple distinct steps, starting with large-scale simulation using NVIDIA Omniverse based on privileged information. Basically, you first need to learn policy given the (noisy) ground-truth information about, e.g., the pose of the object in the world.
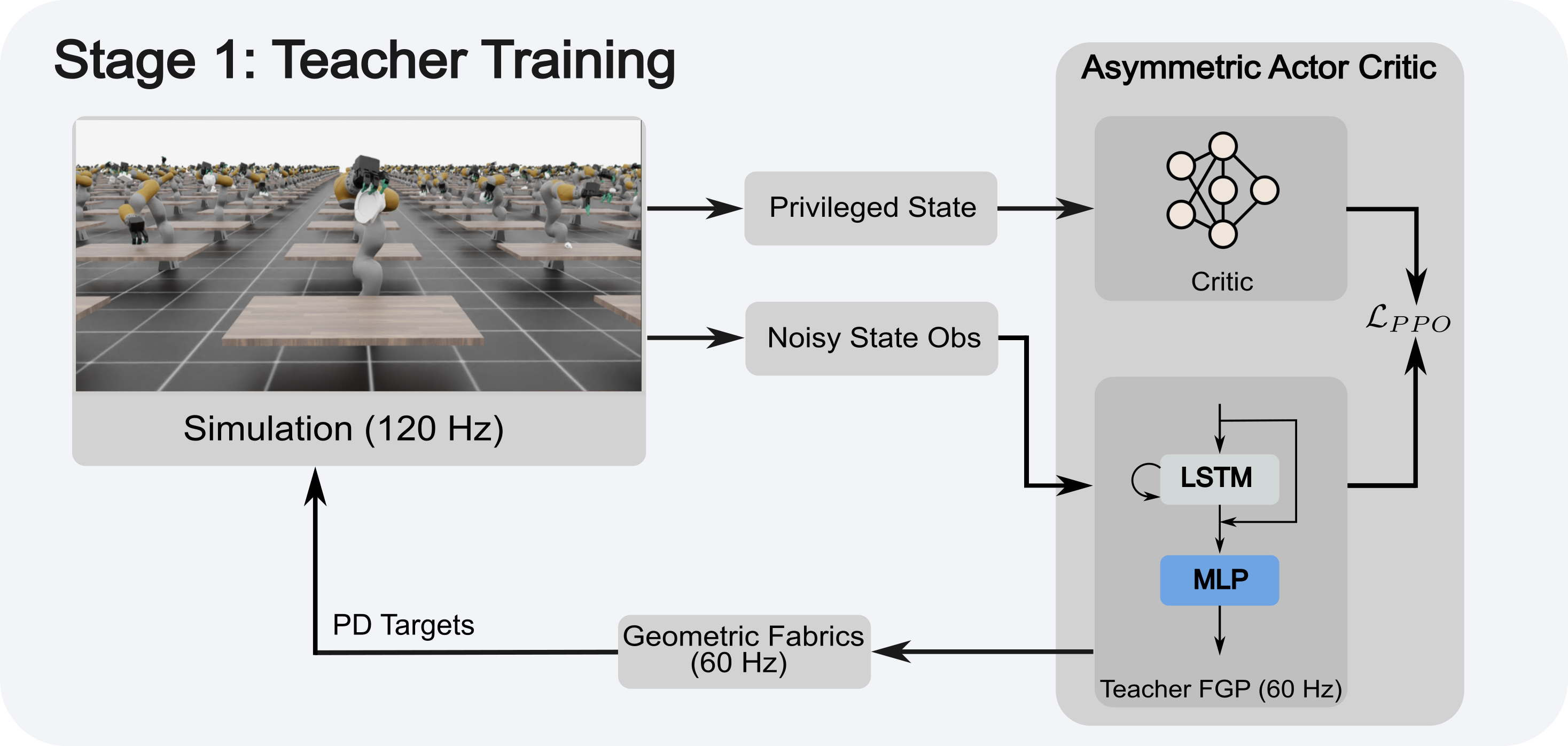
Note the use of Geometric Fabrics [7] here; these are a sort of reactive, high-speed motion planner that has been championed by Karl van Wyk, Nathan Ratliff, and others at NVIDIA for a few years now. They result in really nice, smooth motions, and nicely avoid joint limits and geometry (probably the table). I believe that this will aid the exploration problem that makes RL so difficult.
After this, we have an “expert” policy which will perfectly grasp any previously-unseen object… given the completely unrealistic information that you know exactly where it’s located. So, now we train a perception policy:
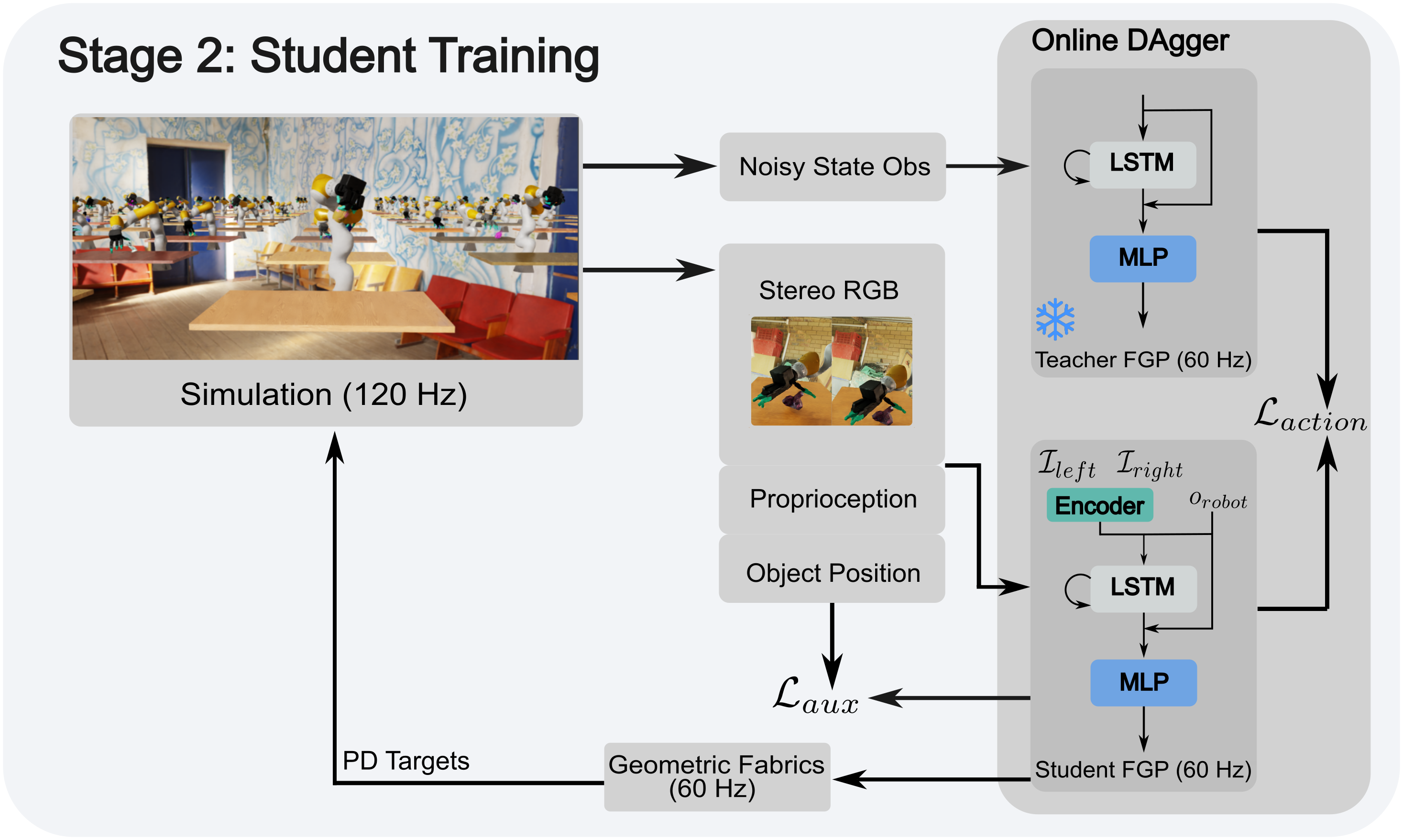
This perception policy takes in stereo RGB images. Here, the authors start randomizing camera and lighting configurations. They distill a policy and can test it with a simple state machine to pick objects off of a tabletop.
ManipGen

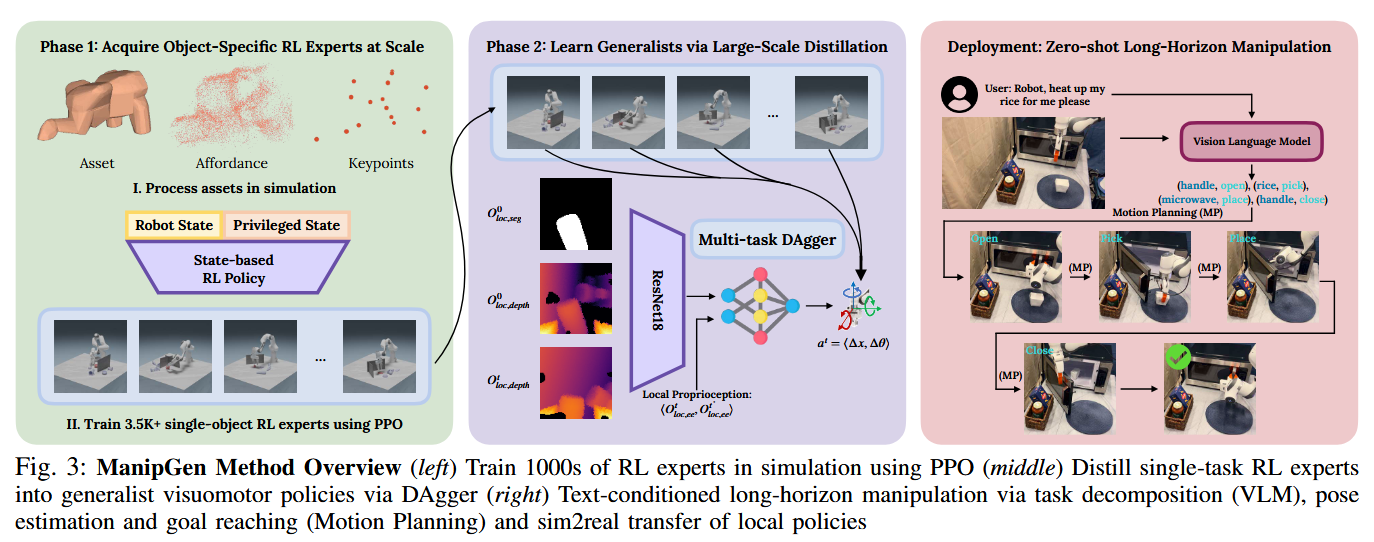
Here, it’s useful to draw a parallel to another paper I quite liked: “Local Policies Enable Zero-shot Long-Horizon Manipulation,” from ICRA 2025.
Similarly, the authors trained a set of multi-object, general-purpose policies, this time for a slightly wider variety of skills like opening doors and picking with a two-finger gripper. Again, they train an expert policy first:

They then distill these into expert policies which can be chained together to perform a variety of complex, long-horizon tasks. In their case. these policies use segmentation and depth data — a combination which transfers very well to the real world, and also allows you to parameterize each atomic, low level policy with a mask that can come from a VLM. All in all, its a nice strategy that then gives you an “API” for constructing long-horizon task plans on tasks for which the robot was never trained.
Sim-to-Real Cotraining
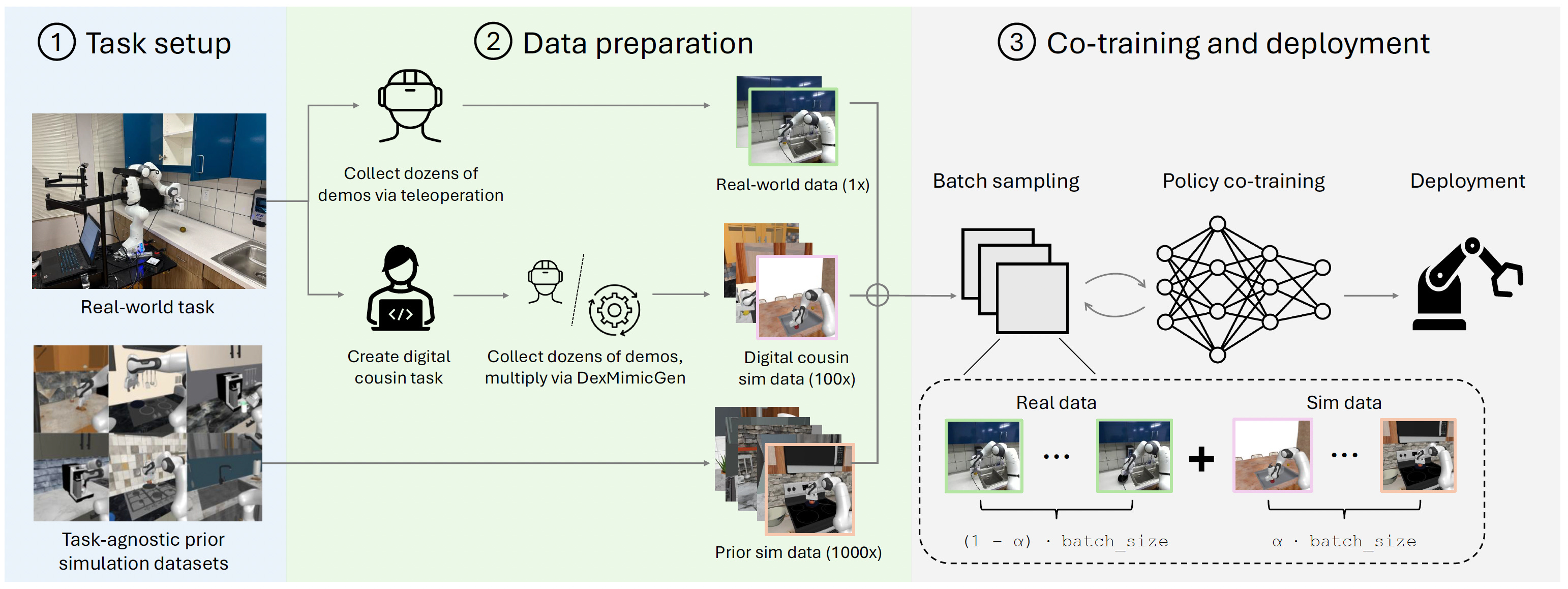
These previous two papers are basically “pure” sim-to-real papers: they don’t have any formal strategy for incorporating real-world data. In the paper “Sim-and-Real Co-Training: A Simple Recipe for Vision-Based Robotic Manipulation,” we see the authors take a different approach:
Collect and pretrain on diverse simulation tasks
Then collect some real world data, and about 100x as much simulation data from “digital cousins”: a variety of similar, diverse simulation tasks.
This lets them use comparatively little real data to perform tasks, while still leveraging large amounts of simulation data. The idea that you can use similar simulations to your target task is really powerful, since it can be difficult to mock up and build an accurate task simulation in a new domain!
Sim-to-Real RL for Dexterous Manipulation
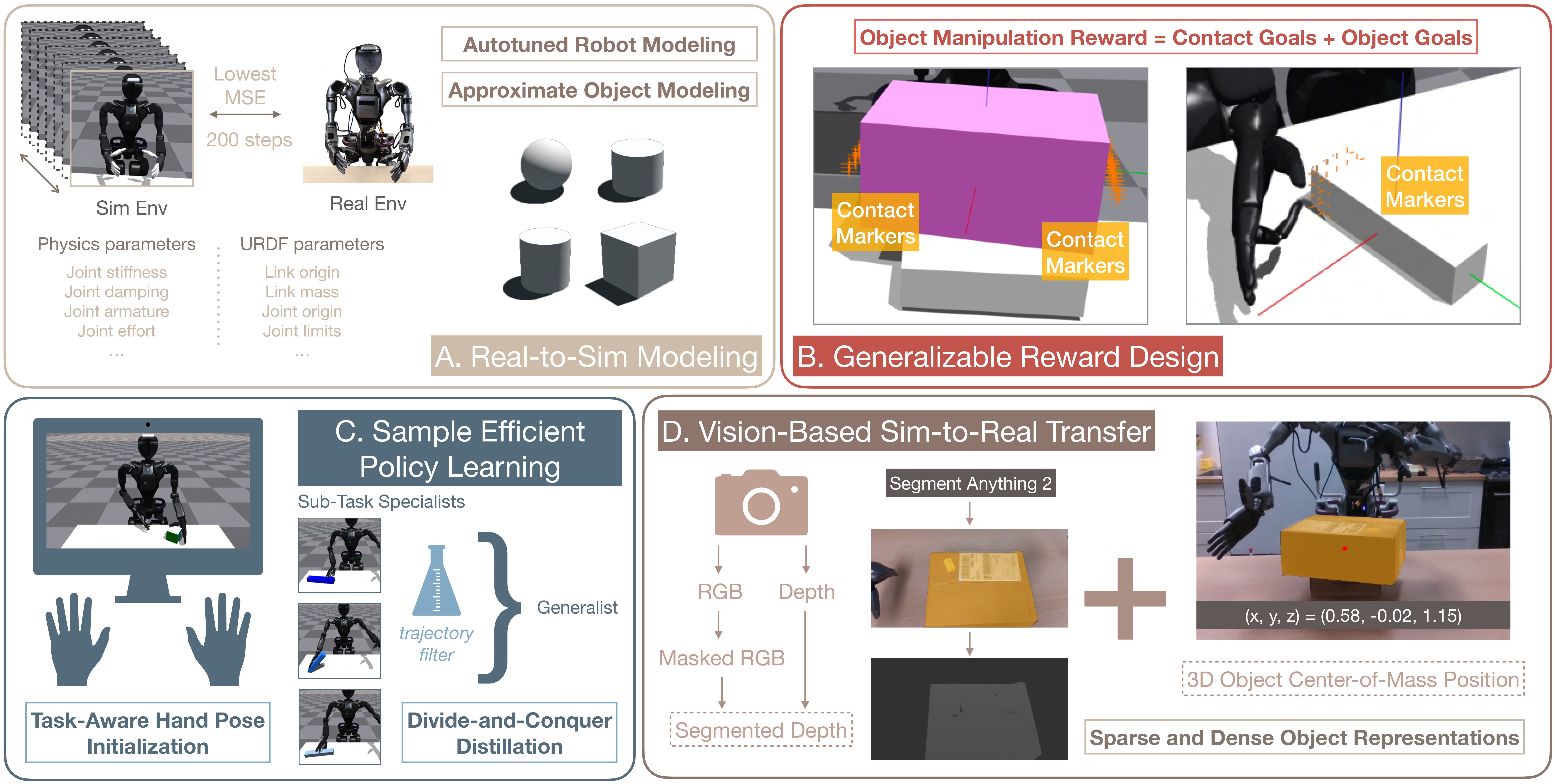
Finally, let’s look at sim-to-real RL. In the paper “Sim-to-Real Reinforcement Learning for Vision-Based Dexterous Manipulation on Humanoids,” the authors train a variety of dexterous manipulation tasks. Here, as with in ManipGen, the authors are learning a policy on segmented RGB-D data — there’s no need for all of the color and lighting randomization tricks we saw in Dextra.
By the way, we have released a RoboPapers episode on this one:

In a way, this paper is quite pure compared to the others on this list: there’s no student-teacher step. There are no real-world demos. There is some real-world data, used to fine-tune simulation parameters to make the simulation match the real-world robot’s properties. They also put a lot of thought into how to do generalizable reward design which works across various different tasks.
Final Thoughts
What lessons can we pull from all this?
1) Decompose into sub problems
Learning works best when it’s clearly scoped. Several of these papers learned small, reusable pieces, or broke up the learning “vertically” into teachers and students.
2) Visual Domain Randomization
The visual domain gap is really hard to close. Either you use a sensor which makes it easier (using segmentation and depth data), or you use lots of color and lighting randomization - possibly both.
3) Real world feedback is useful
Some amount of real-world data is important for getting all of these methods to work. It’s not part of the papers, but both Dextra and Manipgen use a “motion planner” of some sort, which I’d guess reduces the sim-to-real gap. Manipgen is also at least partly powered by VLM, and uses sensors which minimize the sim-to-real gap.
Both Co-training (obviously) and our dexterous RL paper have a step where you adapt the sim to the real world.
Basically, no one is just running “sim to real” from first princples.
4) Keep the horizon short
“But,” you ask, “aren’t some of these performing complex, long-horizon tasks?” Well, yes, but they weren’t trained on them - Dextra and Manipgen use state machines or VLMs to create longer task plans. Sim-to-real RL is already hard enough.
References
[1] Singh, R., Allshire, A., Handa, A., Ratliff, N., & Van Wyk, K. (2024). DextrAH-RGB: Visuomotor Policies to Grasp Anything with Dexterous Hands. arXiv preprint arXiv:2412.01791.
[2] Maddukuri, A., Jiang, Z., Chen, L. Y., Nasiriany, S., Xie, Y., Fang, Y., ... & Zhu, Y. (2025). Sim-and-real co-training: A simple recipe for vision-based robotic manipulation. arXiv preprint arXiv:2503.24361.
[3] Lin, T., Sachdev, K., Fan, L., Malik, J., & Zhu, Y. (2025). Sim-to-real reinforcement learning for vision-based dexterous manipulation on humanoids. arXiv preprint arXiv:2502.20396.
[4] Dalal, M., Liu, M., Talbott, W., Chen, C., Pathak, D., Zhang, J., & Salakhutdinov, R. (2024). Local Policies Enable Zero-shot Long-horizon Manipulation. arXiv preprint arXiv:2410.22332.
[5] Zeng, K. H., Zhang, Z., Ehsani, K., Hendrix, R., Salvador, J., Herrasti, A., ... & Weihs, L. (2024). Poliformer: Scaling on-policy rl with transformers results in masterful navigators. arXiv preprint arXiv:2406.20083.
[6] Lum, T. G. W., Matak, M., Makoviychuk, V., Handa, A., Allshire, A., Hermans, T., ... & Van Wyk, K. (2024). Dextrah-g: Pixels-to-action dexterous arm-hand grasping with geometric fabrics. arXiv preprint arXiv:2407.02274.
[7] Van Wyk, K., Xie, M., Li, A., Rana, M. A., Babich, B., Peele, B., ... & Ratliff, N. D. (2022). Geometric fabrics: Generalizing classical mechanics to capture the physics of behavior. IEEE Robotics and Automation Letters, 7(2), 3202-3209.
Thank you for this insightful post. It highlights the significant amount of work still required in sim-to-real transfer for manipulation. This blog effectively demonstrates that "plug and play" sim-to-real is not as straightforward as it may seem, as the authors perform considerable backend work to achieve their results. I believe that for simulators to become truly effective, they require a further leap in photorealism and physics, as the current level of tooling is a significant hurdle; including modeling the simulation environment. Looking forward to more works on learned simulators and world models