
Paper Notes: Building-Wide Mobile Manipulation
BUMBLE: Building-wide mobile manipulation using VLMs

We’re moving towards a world where we’ll see lots of robots able to perform complex, multi-step tasks in homes and other environments, but to this point we haven’t seen many attempts to do this at really long horizons for open-vocabulary tasks. Now, we have BUMBLE, which has 90+ hours worth of evaluations and a user study! This is in a lot of ways the strongest evidence I’ve seen that we can really build capable, in-home assistants using current technology.
What do I mean by capable? I mean robots that can be given an open-ended tasks like “pick up a sugar-free soda” and actually deliver on them, as per the video above. This involves all of our favorite parts of the robotics stack: localization, mapping, grasping, and, of course, language and image understanding.
What this is not: a new method for representing the world for mobile robots, a topic I reviewed in the past (see link below). BUMBLE uses a skill library and a set of precomputed maps and landmarks; it is not, for example, a process for creating a map without human input like OK-Robot or CLIO.

How Does it Work?

The system works like this
A VLM (GPT-4o, basically) operates as the central planning and reasoning module
A short-term memory tracks robot execution history during individual trials
A long-term memory tracks important information across trials
The VLM can call a set of skills, like moving to landmarks, etc.
A perception system based on GSAM2 detects individual objects in the scene.
The latter four modules all provide prompt information into the VLM, as you can see below. It can then predict a bunch of different subgoals, estimate how to use the skills, etc.

Systems like this can be very complicated. Fortunately, the authors provide open-source code on Github so that we can reproduce their work, and see how it was implemented.
Relation to Other Papers
When I saw this, I immediately think of works like Closed-Loop Open-Vocabulary Mobile Manipulation by Zhi et al, which show reactive task execution powered by GPT. Works like Hierarchical Open-Vocabulary Scene Graphs also allow for complex task execution - although in this case only navigation - using LLMs, and we see works like Language Instruction Motion Planning which build much more explicit 3d maps containing affordance information.

The paper of course has it’s own lit review - you can check that out - so I’ll just share a few thoughts. We’re seeing a concensus on what currently deployable systems look like:
Large vision-language models on their own, without action information capture enough semantic knowledge to come up with reactive, high-quality, long-horizon plans
While these don’t really understand actions per se, they’re a really incredibly capable part of a system which does understand those actions (shades of LLM-Modulo in a way)
These can be used together with skill libraries (optionally learned; often, as in this case, not!) to perform a really wide variety of tasks. If learned, you could collect targetted data to improve these skills.
Compare to OpenVLA and its ilk; we have models which try to do everything all in one architecture, which requires a lot more actual robot data (most of the papers above require essentially none!)
As it’s a core interest of mine, and extremely relevant to how to actually make a system like this work in practice, let’s look at how that memory actually works.
Architecture
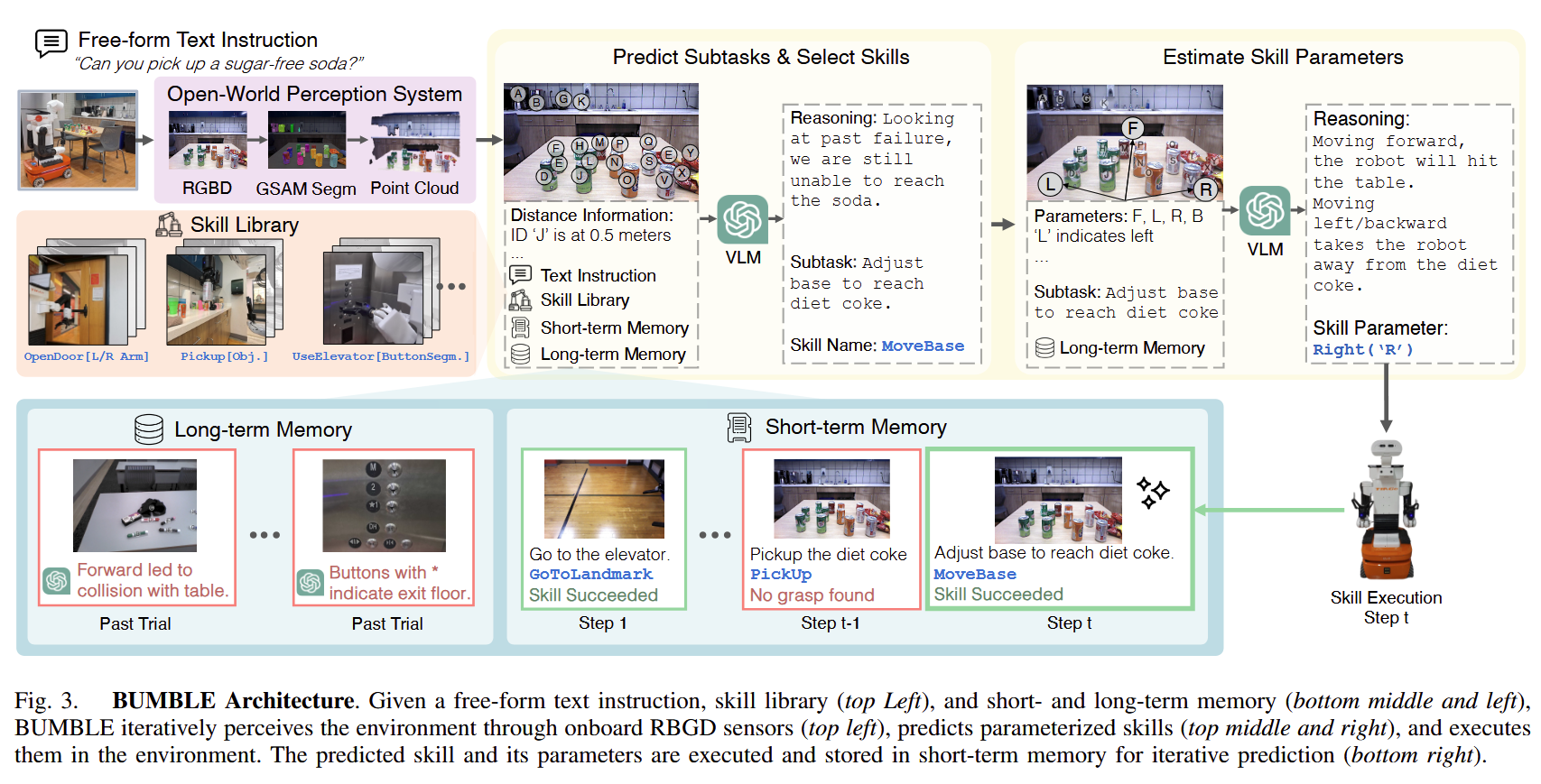
This will be a really short section. So what are those two kinds of memory?
Long term memory stores previous prediction failures, flagged by a human operator. This is nice because it provides a mechanism by which we can (hopefully!) arrive at ideal performance by teaching the robot as it fails to perform tasks.
Short term memory stores action results and failures during a single execution, allowing error recovery and replanning.
Skills are all implemented in their own ways; GoToLandmark, for example, takes a topographical map of the building with occupancy maps for object avoidance.
Some Conclusions
These are the kinds of experiments I like to see: large-scale, long-horizon tests in buildings.
We can see how large VLMs like OpenAI’s GPT4o (but also Google’s Gemini and other similar models) can be used to perform complex, long-horizon reasoning. This looks at how to make embodied AI agents reactive, and also has a nice “lifelong learning” element from the long horizon memory which should allow robot performance to monotonically improve in a building through user feedback.
I think there’s also this clear convergence towards what seems to be working for generally-capable AI-enabled mobile robots, which right now involves:
Maps
A skill library
A large VLM coordinating things
increasingly a memory
And this is a fantastic example of that architecture. Not to say others (the OpenVLAs of the world) won’t work - just that this sort of approach seems much more readily deployable and has a ton of immediate advantages.
References
[1] Shah, R., Yu, A., Zhu, Y., Zhu, Y., & Martín-Martín, R. (2024). BUMBLE: Unifying Reasoning and Acting with Vision-Language Models for Building-wide Mobile Manipulation. arXiv preprint arXiv:2410.06237.
[2] Zhi, P., Zhang, Z., Han, M., Zhang, Z., Li, Z., Jiao, Z., ... & Huang, S. (2024). Closed-loop open-vocabulary mobile manipulation with gpt-4v. arXiv preprint arXiv:2404.10220.
[3] Werby, A., Huang, C., Büchner, M., Valada, A., & Burgard, W. (2024, March). Hierarchical Open-Vocabulary 3D Scene Graphs for Language-Grounded Robot Navigation. In First Workshop on Vision-Language Models for Navigation and Manipulation at ICRA 2024.
[4] Quartey, B., Rosen, E., Tellex, S., & Konidaris, G. (2024). Verifiably Following Complex Robot Instructions with Foundation Models. arXiv preprint arXiv:2402.11498.