


Vision-Language-Action Models and the Search for a Generalist Robot Policy
VLAs are general-purpose robotics models. But how are VLAs doing in the real world. and which ones are people using?


At the UPenn GRASP lab, researchers do something that is still shockingly rare: they download a state of the art robot policy and just used it for a while.
You don’t see a lot of this in robotics; as much as I wish people would download and run models on their own robots, there’s usually no point: the models just wouldn’t work. It’s not just the hardware — basically every research lab has a Franka Panda or a Trossen ALOHA setup these days — but the objects, the camera position, the task choice, and the environment as a whole.
This is starting to change, though, in large part due to the recent rise in what is called Vision-Language-Action Models, or VLAs. VLAs are trained on a large mixture of data, and have a generalization ability somewhat similar to very early large language models.
At the GRASP lab, their goal was to subject pi0 to the kind of “vibe check” evaluations that we most commonly associate with large language models. They tried the model “out of the box,” without fine tuning, and saw that it got an average success rate of about 42.3%. That may not sound like a lot, but for a robots model, again, this is massive: people just don’t do this sort of thing.
Part of the reason this works as well as it does is because VLAs like pi0, as well as similar models like NVIDIA’s GR00T, are trained on a very large mixture of data. They can be prompted with natural language, something that the researchers found made a big difference.
As a result, the dream of a general-purpose robot seems closer than ever. Robotics models like pi0.5 show robust, real-world generalization to new environments and new scenes.
But what are these models like? What kind of architecture do they use, how do they predict actions, why exactly is this data mixture so useful, and what are the limitations? Let’s take a look.
What is a Vision-Language-Action Model?
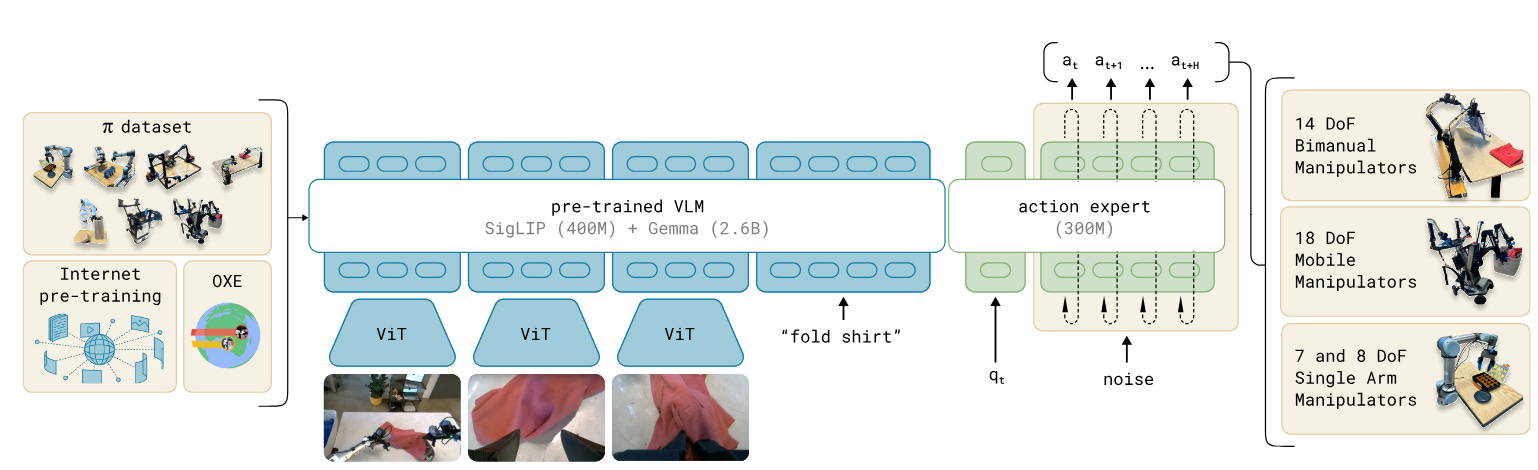
Vision-Language-Action models — VLAs — are large multimodal transformer models which predict robot actions, given observations from multiple cameras. They’re usually trained based on some pretrained vision-language model — PaliGemma for Pi0, Eagle for GR00T, etc. This means that before the models even see any robotics data, they already have a lot of knowledge of the world just baked in.
The architectures, as a result, all end up looking a bit similar. State information - robot joint position encoders mostly - is completely absent from the VLM head on top, and is usually only fed into the “diffusion policy” equivalent section making action predictions.
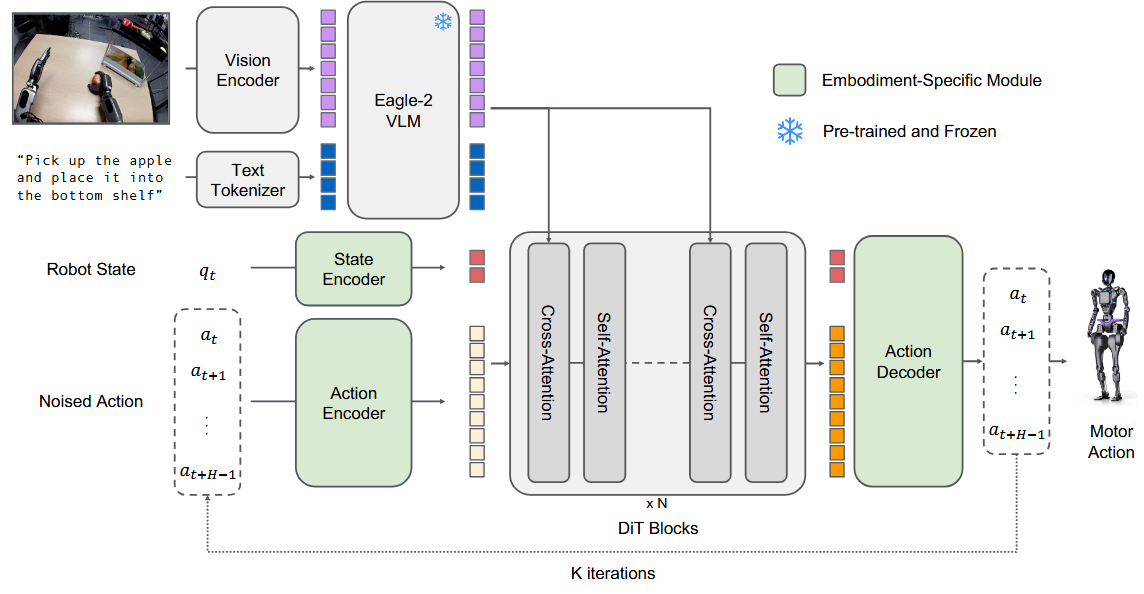
The GR00T architecture, above, is another solid example, taking in state and (noised) action information and using these to predict an upcoming trajectory snippet.
We can see a similar architecture in the recent TRI “large behavior models” work, though with one notable caveat; in this case, instead of a full-fledged VLM, they just use the CLIP image and text encoder. CLIP is a powerful but comparatively lightweight image-language encoder that’s been used in various cool robotics projects. But take a look at the architecture:
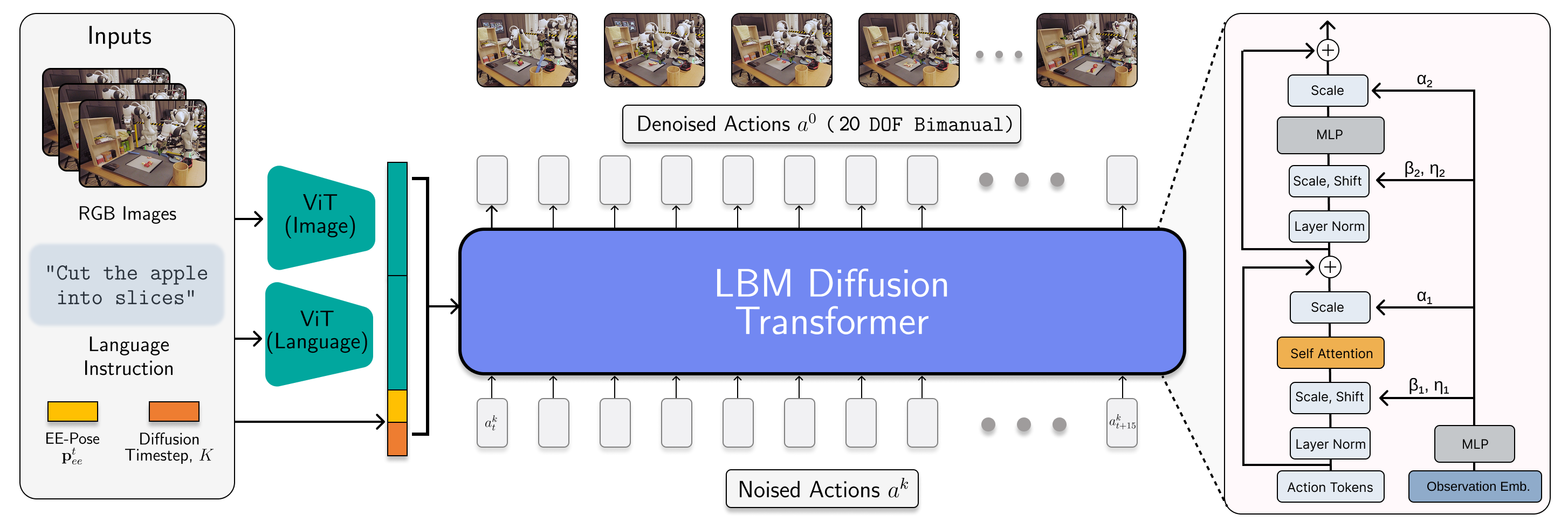
Again, we see some webscale-pretained component which can extract image and language tokens, which conditions a relatively large multi-task diffusion transformer model. These models have since been applied to mobile manipulation with the Boston Dynamics Atlas humanoid.
While we’d expect substantially less language generalization and reasoning ability from the stripped-down LBM, on the robotics side the capabilites should be fairly similar, so for the purposes of this blog post I’ll also consider it a VLA. And one final note: practically speaking, the policy component of any of these models also uses an architectures inspired by image generative models, like diffusion transformer.
Thinking Fast and Slow with VLAs
There’s an interesting parallel to human cognition here. As I said above, VLAs have both a “vision-language model” head — a general purpose visual encoder, which converts images into tokens — and a diffusion policy (-ish) output. This has a certain similarity to the idea of human cognition laid out in Thinking, Fast and Slow:
System 1: Fast, automatic, frequent, emotional, stereotypic, unconscious.
System 2: Slow, effortful, infrequent, logical, calculating, conscious.
Here, the Diffusion Policy - which takes in robot state information, and makes action predictions - is the System 1, and the VLM - which takes in language and image information and provides valuable context and goal-setting for the diffusion policy - is System 2. Works like GR00T N1 and Figure Helix directly make this parallel.
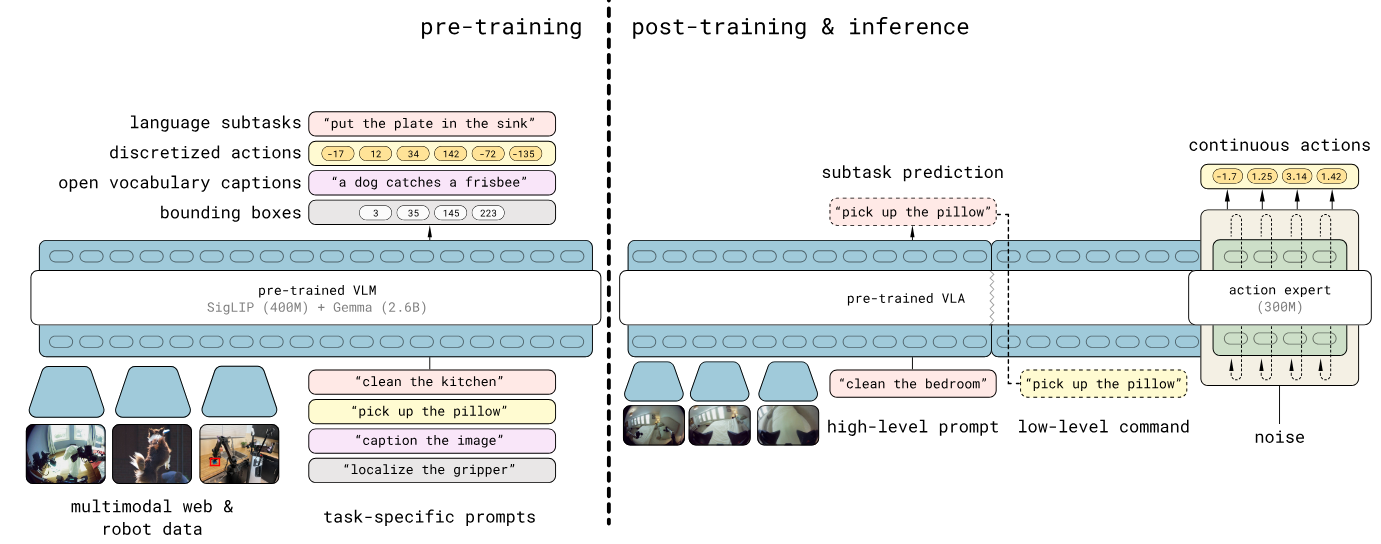
An extremely clear example of this structure is pi 0.5 from Physical Intelligence: they have their “System 2” output a set of discrete tokens, learned via the FAST action tokenizer, which are then inputs into the flow matching System 1 architecture. Note that while I’m not covering what flow matching is here, it’s serving the same purpose as the “diffusion policy” heads the rest of these models are doing — always safe to assume that Physical Intelligence is the most algorithmically advanced, though.
Why use a VLA?
In short, robustness and generality.
VLAs leverage the general-purpose features learned from a broad mixture of training data, in order to train models which are substantially more robust to variation than previous methods. For example: Microfactory creator Igor Kulakov tested GR00T, pi0, and pi0-fast on a suite of tasks. Here’s a comparison he did to Action Chunking Transformer (ACT):
ACT is a “standard” imitation learning method at this point, proposed in ALOHA. This is one of the works that really kicked off our current wave of imitation learning excitement, and it really deserves a deeper look on its own. What’s relevant here is that it’s a single-task model, an action specialist trained only on this one task — and it works significantly worse than the general-purpose models (70% success rate vs. nearly 100%), even though pi0 and GR00T and so on had never seen Kulakov’s robot during pretraining.
The Toyota LBM-1 project is a good study of the capabilities of these models. They investigated a few challenging, long horizon tasks like:
Slicing and coring an apple with a knife
These are complex, multi-step tasks, and it took 1,700 hours worth of data to train them to a decent standard. Similar to the results above, though, the Toyota VLA fine-tuned with only 15% of the available data outperformed a single-task baseline.

As another point of comparison, we can look at ALOHA Unleashed, a somewhat older paper from the Google Deepmind team which performed a large number of very long horizon tasks: hanging up a shirt, tying shoelaces, etc. However, these were all diffusion policies that were trained separately. Each one of these single-task models took 5,000-6,000 demonstrations! While all of these models require a lot of data, there’s still a massive improvement from fine-tuning the multi-task model.

VLAs are also co-trained on a wide variety of different tasks: image-based question answering and captioning (using the visual heads), human trajectory, etc. GR00T, for example, was trained on object detection as an auxiliary task. Google Deepmind’s Gemini Robotics takes this particularly far in their own work, as shown above: they train on a really wide range of different tasks, like 2d pointing and 3d object detection, all of which can be useful to downstream robot task execution.
The end effect is that these models can be expected to have a very strong understanding of a wide variety of environments and robotics tasks, in addition to many of the “classic” tasks that flagship large multimodal models are trained on.
What VLAs are People Using?
There are a few different vision-language action models out there. It seems that most big robotics companies have their own or are planning to build their own. But a few usable VLAs that come to mind are:
Physical Intelligence has pi0, which is widely acknowledged as the state of the art, although pi0.5 — with a notably different architecture — has shown some truly impressive results.
RT2 and RT-X were the first “major” vision-language action models, from Google Deepmind. RT-X in particular is associated with what is still the largest open robotics dataset, Open X Embodiment. However, these models are somewhat out of date right now.
GR00T N1 is an open foundation model for robotics from NVIDIA. The released version is a 2.2B parameter model based on NVIDIA’s Eagle VLM; the team has since released an updated version, GR00T N1.5.
Google Deepmind’s Gemini Robotics model has been released to trusted testers, but isn’t publicly available yet, though they did recently release a smaller on-device VLA.
Toyota and Boston Dynamics have recently been using the Large Behavior Model (LBM), which is sort of a stripped-down VLA without the complex language generalization abilities noted in other works.
This is a fast moving area; there is a ton of interesting work going on in VLAs (I’ll save a roundup of interesting Vision Language Action models for a future post), but we can see iterations on the “standard” VLA architecture by major labs like TRI (see their work “A Careful Examination of Large Behavior Models for Multitask Dexterous Manipulation”) and ByteDance (their Seed GR-3 VLA).
Limitations of the VLA

Current VLAs are not by any means perfect. Users report all kinds of weaknesses, including lack of collision avoidance, lower success rates, and failures at fine-grained manipulation. We’ll look at a few specific problems, though, that we need to address.
Limitation #1: Action Inference
Take a look at this video, again from Igor Kulakov, of a pi0 policy he trained and deployed on his custom arms for manufacturing. Notice that it’s stuttering:
The problem is that action inference is quite slow — slower than real time. This is actually not inherently a quality of the VLA. Certainly precursors to modern VLAs, like Google’s RT-2, did not have this limitation but could execute at a slow-but-reasonable 5 hz. Diffusion policy (-ish) outputs, however, are fairly slow, and require multiple passes through the transformer to refine noisy action predictions.
This isn’t a problem for most tasks. But for highly dynamic and reactive tasks, you might end up with an issue - certainly, if the world is changing unpredictably faster than inference time, the robot is not going to be able to keep up.
Limitation #2: We Need Bigger Datasets
This is something I’ve covered before on this blog, and will certainly cover again, but robotics has a massive data gap. We’ve tried many, many different ways to overcome it, and will undoubtedly try many more.
How can we get enough data to train a robot GPT?

It’s no secret that large language models are trained on massive amounts of data - many trillions of tokens. Even the largest robot datasets are quite far from this; in a year, Physical Intelligence collected about 10,000 hours worth of robot data to train their first foundation model, PI0.
Most VLA efforts use a combination of methods to at least reduce the impact of the robot data gap.
These data choices also make a huge difference: GR00T, for example, heavily uses the Fourier FR1 humanoid while Physical Intelligence’s pi0 heavily uses the Trossen ALOHA setup in its real-world data. A lot of people have Trossen arms; very few have the Fourier GR1. That means that all else being equal, most people will have a much easier time using Physical Intelligence’s models than NVIDIA’s.
This particular problem would go away if everyone had just kept contributing to Open-X Embodiment like they were supposed to. But data is expensive, it’s the new coding, and in a very real way it’s your “moat”: it’s unreasonable to expect private companies to share large amounts of data freely.
Limitation #3: You Need a Lot of Compute
Groot N1.5 was trained on 1,000 NVIDIA H100 GPUs. That’s $25 million if you want to actually build out a cluster capable of training robotics models. And this is almost certainly too little — if we want to use neural trajectories, as the GR00T team is planning to do, that’s compute you’ll need as well. And, if anything, these current VLAs are too small.
All of these model architectures hover around 2-4 billion parameters. But as with every other area of robotics, we should expect performance to scale with good data and compute — we should be able to use larger vision encoders and larger policy architectures with more data, and thus, see better performance. Note that, for example, the 4 billion parameter ByteDance GR-3 model seems to outperform NVIDIA GR00T and Physical Intelligence pi0, both of which are roughly 2 billion parameters. It’s safe to assume that scaling laws will hold here, once we have the data and compute to support them.
Final Thoughts
The specific problems people note with VLAs — their accuracy, their instability — all seem to boil down to these three above: a fundamental weakness of the diffusion output, and the need for substantially more compute and data than we currently have.
All this being said, the VLA is here to stay.
The network architecture seems remarkably consistent, being employed by top research labs as well as by humanoid robotics startups. Its advantages in combining disparate data streams — egocentric human video, “data collection” tools, simulation, and the always-crucial real-robot data are undeniable.
The most exciting work in VLAs right now comes down to reliability, something that we’ve seen from the robotics startup Dyna Robotics. DYNA-v1, their first foundation model, with which they were able to reach a 99.4% success rate at a napkin folding task for one of their first customers.
As noted above, there are a lot of places where current models fail. To some extent, it seems clear that these issues can be solved with more data, and in particular more of the right data. Getting that “right” data is hard, and something we’ve discussed before in this blog, at least it’s a very concrete problem.
Overall, though, it’s interesting to see the convergence here — how the field as a whole is converging on a set of similar tools and architectures, all pretrained on webscale data, and how these are starting to yield truly general-purpose robotics base models which can be used in a variety of contexts.
References
[1] Wang, J., Leonard, M., Daniilidis, K., Jayaraman, D., & Hu, E. (2025). Evaluating π0 in the Wild: Strengths, Problems, and the Future of Generalist Robot Policies. Source
[2] Black, K., Brown, N., Driess, D., Esmail, A., Equi, M., Finn, C., ... & Zhilinsky, U. (2024). π0: A Vision-Language-Action Flow Model for General Robot Control. arXiv preprint arXiv:2410.24164.
[3] Bjorck, J., Castañeda, F., Cherniadev, N., Da, X., Ding, R., Fan, L., ... & Zhu, Y. (2025). Gr00t n1: An open foundation model for generalist humanoid robots. arXiv preprint arXiv:2503.14734.
[4] Intelligence, P., Black, K., Brown, N., Darpinian, J., Dhabalia, K., Driess, D., ... & Zhilinsky, U. (2025). π0.5: a Vision-Language-Action Model with Open-World Generalization. arXiv preprint arXiv:2504.16054.
[5] Cheang, C., Chen, S., Cui, Z., Hu, Y., Huang, L., Kong, T., ... & Yang, Y. (2025). GR-3 Technical Report. arXiv preprint arXiv:2507.15493.
Great post!
Do you consider the MolmoAct project and Action Reasoning Model (https://allenai.org/blog/molmoact) just another VLA or do you think they are doing something different/novel? Thanks.
> This particular problem would go away if everyone had just kept contributing to Open-X Embodiment like they were supposed to. But data is expensive, it’s the new coding, and in a very real way it’s your “moat”: it’s unreasonable to expect private companies to share large amounts of data freely.
I’m hoping that over time, LeRobot catches on in the research and hobbyist community and eventually all we’ll have to do is go through and aggregate it. It already seems to have some sway - IK SmolVLA used LeRobot data and iirc GR00T trained on SO100 data.