
Why Is DreamZero So Good at Robotics Benchmarks?
A new model from NVIDIA has crushed top new benchmarks; what is different about it from the previous best model?


The team at NVIDIA recently released a set of robotics models; one that’s been driving a lot of discussion online lately has been DreamZero: a “World-Action Model” which predicts video in addition to robot actions. In particular, it achieved benchmark-topping results at two very interesting benchmarks this week: RoboArena and MolmoSpaces:

Let’s briefly go over what this means and what we might learn from these results. In this blog post I write:
A very high level look at what makes DreamZero different from other policies and world models
A brief look at RoboArena and MolmoSpaces
Some speculation about what’s different and what might be causing performance gains
A lot of this was pulled from discussions on X. Upcoming content: we will have a RoboPapers podcast on DreamZero in the next few weeks, and next week on this blog I should have a more in-depth analysis of world models and how the landscape has changed in 2026.
What is DreamZero?
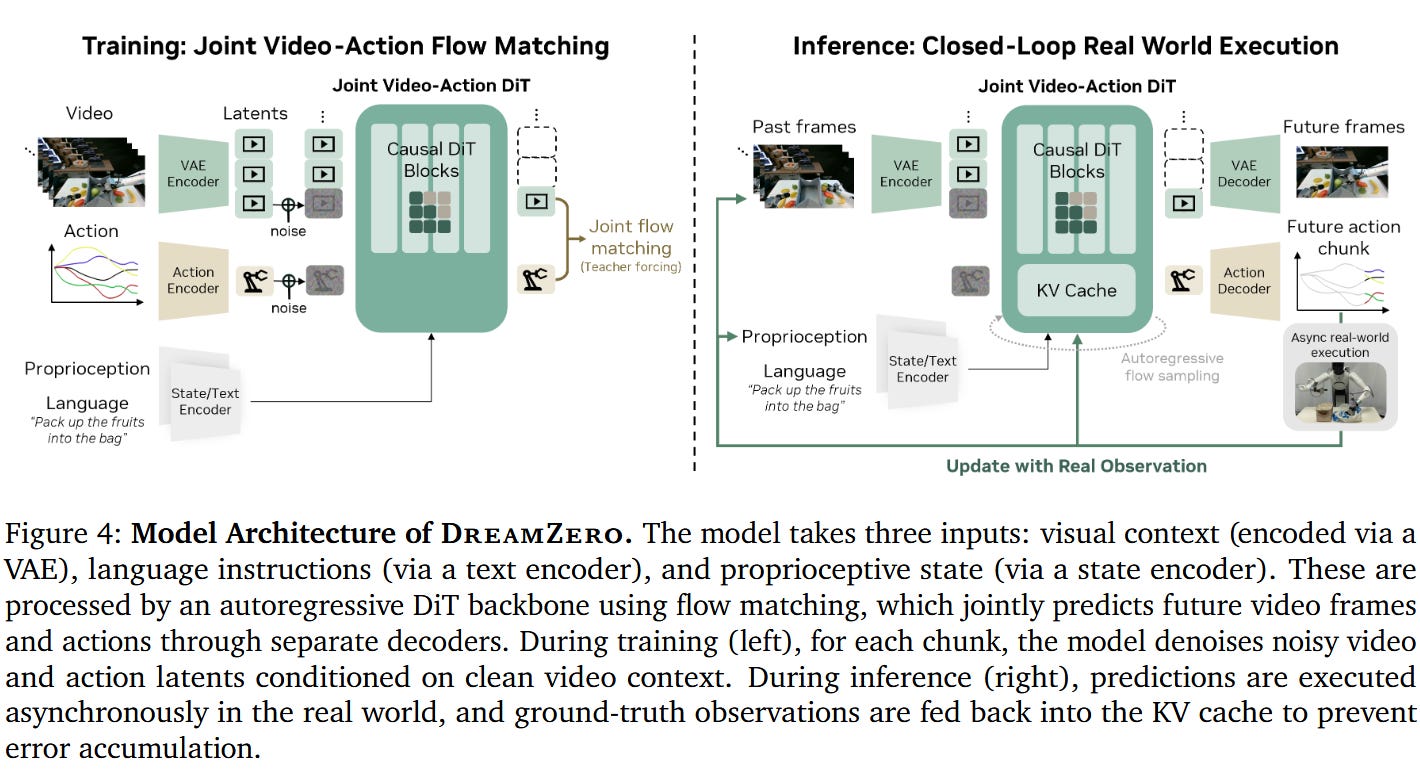
DreamZero is a “world-action model” from NVIDIA. In practice, this takes a lot of the concepts from world models — principally that video generation is useful for robotics — but changes the formula in a couple key ways. Most crucially, it jointly models action generation and video generation.
Usually, there are two classes of world models:
Action-conditioned world models learn the mapping x’ = f(x, a), for state observations x and actions a. An example would be V-JEPA 2 or the world model from the recent RISE paper.
“Inverse dynamics” world models like NVIDIA’s DreamGen or the 1x world model (RoboPapers podcast for DreamGen, RoboPapers podcast for 1x), which learn x’ = f(x) and then an inverse dynamics model a = g(x, x’)
This model is much more like a traditional robot policy, but also predicts future video - so we are learning something more like (x’, a) = f(x). All of these are a huge oversimplification of the true training objectives, of course — read the paper for details.
You can also compare to a traditional vision-language-action model: we are also predicting what the future will look like. This gives a much richer supervisory signal over how the world will evolve going forward.
The Benchmarks
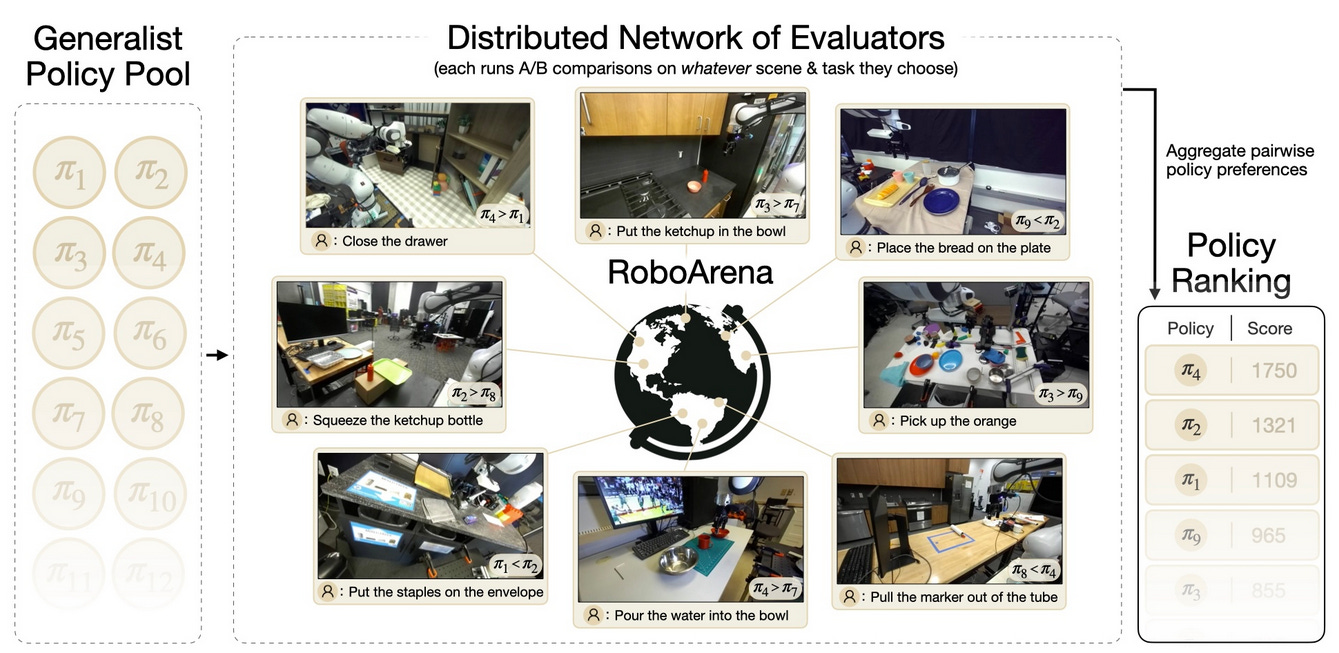
RoboArena is a distributed “real world” benchmark based on Droid. Evaluators across the world have somewhat similar robots and setups, and run a set of open-ended robotics evaluations with different natural-language commands.
This means that it’s somewhat in-distribution for DreamZero, as it was trained on Droid, which contains very similar tasks and setups. But it’s still a real-world evaluation, with all the difficulties and changes that this implies; and the tasks are chosen by evaluators. It’s also a “head-to-head” comparison benchmark, similar to the Chatbot Arena which was so influential in LLM development. I wrote about this at length in my post on robot learning evaluation.

MolmoSpaces is a new benchmark, with high-fidelity physics and diverse, procedurally-generated environments. MolmoSpaces-Bench, in particular, is a test of controlled variation across a variety of pick, place, open and close tasks, plus compositions thereof.
It’s a new benchmark that’s definitely not close to saturated yet. And DreamZero performs well on both:

What Can We Learn?
Let’s compare pi-0.5 with DreamZero, specifically, as pi-0.5 is the second best.
Training data: pi 0.5 was trained on 10k+ hours of real robot data, VLM data, and data from the Droid dataset, as Mahi Shafiullah points out on X. DreamZero was trained on either DROID data or Agibot data, depending on the model checkpoint.
Training data distribution likely makes a huge difference here. Notice how in the DreamZero paper, Dreamzero radically outperforms pi-0.5 on AgiBot (not represented in the pi-0.5 training data) but is much closer on the shared DROID-Franka setup:

This also seems to suggest to me that possibly the additional 10k hours of robot data is not as useful as people think. Pretraining on the right robot data does seem very important; in another recent blog post, Physical Intelligence showed a massive gain from pretraining on in-distribution partner data:
So, maybe adding in an extra 10k hours from a different robot is actually no better than whatever random video data you happen to have. This would likely be a bad result for people who want to train cross-body robot brains. Perhaps you’re not getting anything from those other robot embodiments that you wouldn’t get from just adding cheap, plentiful egocentric video data.
Model backbone: DreamZero is based on Wan2.1-I2V-14B-480P, a 14B-parameter video generation model. It can take up to 8 frames of context. By contrast, pi-0.5 was trained based on the 3B-parameter PaliGemma open-source VLM. So, a much smaller model. It’s also one that takes only a single frame instead of an 8-frame history. This has ramifications for any task which is partially observable or has hard-to-model dynamics, which is to say any real robotics task.
Model size: DreamZero is a huge model, and much of the work in the paper is actually around making this massive, 14B parameter model run in real time. Ablations in the paper seem to show that model size makes a very large difference here:

The problem with both including more history, and with increasing model size, is that this would usually make the model both harder to train and cause it to “overfit” more in a low-data regime. Unlike LLMs, where overfitting really isn’t an issue due to abundance of data, in robotics we’re essentially always operating in a low-data environment, even now. DROID is tiny compared to even the smallest LLM datasets.
So, a proposal: the video-generation objective functions as an “auxiliary loss,” forcing structure on the DreamZero model and causing it to learn some internal model of the world. It provides a comparatively strong form of supervision compared to the sparse signal from robot actions. This in turn makes it better able to adapt to the varied MolmoSpaces environments that it was not trained on.
Final Thoughts
There is a lot we can’t determine just from these papers. We don’t have access to all the data that Physical Intelligence used; it’s still hard to access the GB200s that NVIDIA uses for inference. But to me, it’s exciting to see that perhaps we don’t need nearly as much data as was previously thought to get strong real-world robot results, and I hope to see more work in this direction.
One last question I have is this: if video generation is “just” an auxiliary loss, how long will we need it? In a world with thousands of intelligent robots deployed, will this eventually be distilled away, and will all of these models just be beaten by dedicated robot video models with robot-specific fine tuning? This seems very likely, but is potentially a couple years off.
Please let me know what you think below.
I buy that video gen models should be better than VLAs. Having the core of the model be image/video makes more sense than having the core of the model be text.
My question is, what data will improve video generation accuracy? The authors cite that as the primary weakness, not the IDM.
I guess more video in pretraining, but surely there is a more effective post-training recipe/set of ingredients.
I think the "auxiliary loss" framing deserves to be pushed further.
Predicting future video isn't just regularization. It forces the model to build something closer to a causal model of physics. That's a far richer signal than action labels alone, which are essentially waypoints with no information about why those waypoints are correct. In a low-data regime like robotics, that difference compounds fast.
One thing I've been thinking about: this reframes your closing question. To me, the question might not be "will video generation be distilled away" but "what form of world representation survives the distillation?" You'd distill away pixel-level generation, but the causal reasoning it produced would need to be retained somehow. Whether that's achievable without the video objective as a training scaffold feels like the deeper open question to me.
Looking forward to the RoboPapers podcast on DreamZero and your deeper dive into the world models landscape next week.