
How Close Are We to Self-Improving Artificial Intelligence?
New research papers about self-improving AI systems come at the same time as agentic AI is growing more capable, and predictions from AI leaders grow more dire. What does it all mean?


Something strange has been happening recently. AI agents are creeping forward in many different domains, at the same time as we see more and more dramatic predictions from AI industry leaders about job losses and the future. Surely part of this is marketing: AI companies need to sell their products. But the growth is real: across many different industries, AI uptake is skyrocketing. And underneath it all, there is real and growing concerns about what the future will look like.
It’s not hard to see why, when we see stories like this one: OpenAI convened a secretive meeting of mathematicians to come up with more challenging problems for their newest models, an effort which appears to have largely failed.
AI 2027 lays out a thought-provoking scenario, in which AI agents grow more and more powerful. This culminates in an AI agent designed for recursive self improvement in January 2027, in the hopes of creating an intelligence explosion. This leads to a self-improving AI system in mid-2027, potentially leading to massive job losses and AI-managed factories churning out a million robots a month.
But this is only one potential future. How likely is it? How close are we to building AI systems which can take actions in the virtual world, self-improve, and begin to dramatically reshape and rebuild our economy? Are we actually on the verge of AGI, as some have suggested? I posit that:
If we are to see an intelligence explosion in the next 2-3 years, the research trends that lead to that explosion will be visible now.
In this post, I want to look at some actual research papers — concretely describe what current self-improving systems are doing, and what that tells us about the future. Others (Dwakesh Patel, Nathan Lambert) have written better pieces than me about the likelihood of an intelligence explosion, but they aren’t writing about how these things actually work right now. So let’s start with this thesis:
Self-improving AI will arrive in one of two ways:
As “reasoning” large multi-modal models which can iteratively improve themselves via self-practice or some other method; or
As “agentic” systems which can update and improve their own code, and can therefore use tools to solve increasingly challenging problems.
But first, if you, like me, are interested in the technical details about how AI systems work, please consider subscribing, liking/sharing, and definitely leave a comment:
What are AI Agents?
We’re used to computers that are tools — they do one thing, they do it quickly, and we move on. But increasingly we are exploring the potential of AI agents: AI systems which reason, plan, and pursue goals on behalf of users. Now, we’ve long had “task planning” systems that can perform long, multi-step tasks autonomously, like this example of building-wide mobile manipulation from robotics:

What’s different now is that, due to the multimodal nature of modern large vision-language models, they can actually act on natural interfaces that were designed for human users. In cases like the Building-Wide Mobile Manipulation above, we see that the system is actually incredibly complex:
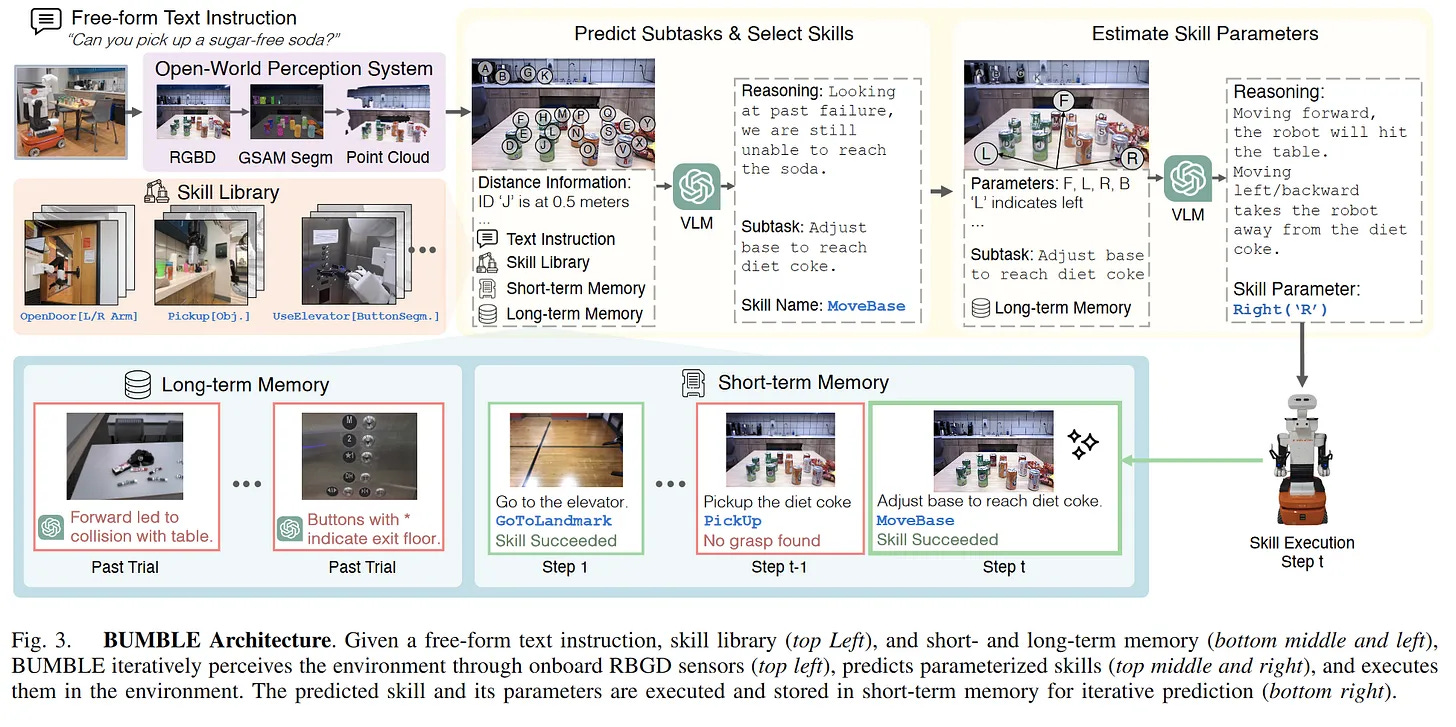
And this, correspondingly, means that there are a lot of places where our system can fail. If a system has 10 components with a 95% success rate, then it has a < 60% overall success rate!
So, we can use modern AI tools to build complex systems capable of satisfying vague, long-horizon goals, both in virtual tasks and (increasingly) in real-world robotics tasks. The problem is that we need ways to improve these systems to approach high levels of performance, in order for them to really start to change things.

We’ll look at two avenues to improving agentic systems capable of accomplishing long-horizon tasks for humans:
Improving the transformer-based models upon which our agentic systems work
Improving agentic systems themselves as a whole
Building Self-Improving Transformers
The transformer is the fundamental building block of an AI system which can take actions and interact with the world. The transformer architecture is uniquely suitable for this role; it can represent many different data modalities, from actions to images to text.
One fundamental step would be to build AI models that can recursively self improve forever. An example loop might go like this:
Take an AI system with a powerful base model and advanced reasoning capabilities
Have it generate a new and more challenging set of problems
Use something (maybe majority voting, maybe test-time compute) to find good answers
Train on the new, better solutions and repeat.
In the paper Self-Improving Transformers Overcome Easy-to-Hard and Length Generalization Challenges [1], the authors look at this based on majority voting. They look at a range of problems, like maze solving and multiplication:

The problem is that many of these problems “scale” well, in a way that perhaps more open-ended reasoning questions do not. These are, as the authors point out, easy-to-hard problems, where each stage clearly builds upon the previous one.
Most human problems can be decomposed, but not as cleanly. Another issue with schemes like majority voting or test-time compute is that they’re essentially just pulling out capabilities that already exist in the models: as noted in my post on reinforcement learning, the base models are already extremely powerful, and that if you draw large numbers of samples for a given question, the large pool of samples from the base models is actually more likely to contain the solution than refined models based on it.
Using Reinforcement Learning to Improve LLMs
Reinforcement learning is, at its most basic level, the study of learning systems that can self-improve over time. I’ve written at length about reinforcement learning and what I see as its current limits. There is a set of problems where we know modern reinforcement learning works very well. To summarize:
You want a verifiable domain: math, coding, etc., so that you know what and when something is successful.
You can find or generate loads of data in this verifiable domain, and have a way of exploring the problem space, but may struggle to determine the path to good solutions.
The problems are all bounded and well-posed.

This is obviously a huge issue when it comes to open-ended reasoning problems like our hypothetical self-improving AI agent, because these sorts of are generally ill-posed. When I set out to write a blog post like this one, for example, I don’t actually know what will end up in the post, what it should contain, or what constitutes a good summary of the topic. This makes reinforcement learning trickier to use outside of certain very impactful but highly limited domains.
But there is some evidence that even reinforcement learning in clearly-defined domains with verifiable rewards can help learn more general-purpose reasoning — something we’ve seen in reasoning models like OpenAI’s o1-o4 models, and in Deepseek R1. So, let’s talk about using those verifiable rewards.
How Well do Verifiable Rewards Work?
“Verifiable rewards” are very common in domains like math or coding, where you can programmatically verify the correctness of an LLM’s output. This solves the “reward function” problem, to an extent, since you can cheaply grade the solutions the LLM comes up with, which should let the reinforcement learning algorithm come up with better and better solutions. We call this Reinforcement Learning with Verifiable Rewards (RLVR), and it’s a really exciting current research area, which has produced a number of exciting results.
There’s something strange thing about these recent RLVR results, though. First, researchers found you could succeed with only a single example [2]. Then, others showed how you can train LLMs with weak or spurious rewards — even random rewards [2] — and still get an improvement!

As it happens, all these results were on Qwen 2.5, and Qwen’s math models were trained on very, very similar problems; even randomly-assigned rewards will, over time, decrease the distribution of things the model generates; as the model is already quite likely to generate the right solution, this increased confidence translates to increased accuracy, all with no “real” increase in capabilities. For more, read Nathan Lambert’s post on the paper.
A couple strange findings like this obviously don’t invalidate an area; they just serve as a reminder about how we should always be skeptical of truly astounding results. And, as is always the case, be wary of hidden biases in your data.
More important are some notes from the Deepseek R1 paper. To summarize:
Deepseek initially trained using RLVR, but quickly lost its ability to do more general reasoning
This was restored through a mixture of reinforcement learning from human feedback (RLHF), fine tuning, and various other purpose-built rewards, often trained from classifiers.
So, RLVR is just not enough for general-purpose reasoning. As I’ve noted before, these approaches work best on really well-defined problems, and building models which can improve themselves is inherently a pretty ill-defined problem.
Can We Move Past Verifiable Rewards?
If we cannot manually specify a verifiable reward, then clearly the answer is that we need a learned reward signal of some kind. The question, then, becomes: how can we train general-purpose reward functions in a scalable, data-driven way?
To some extent, we already do this; reinforcement learning from human feedback (RLHF) works by training a reward function based on human ratings of which answers are preferable to which other answers. The problem with RLHF is that it’s not scalable; the reward functions learned are only locally useful. If you run RLHF “until convergence,” your results get worse.
Recall that an autoregressive transformer is going to sample tokens sequentially, one at a time. This means that there can be a difference between the generated tokens and the optimal sequence of tokens. This implies that we could use the LLM’s confidence in its answers directly as a reward signal, and train on that [4], as described by Mihir Prabhudesai on Twitter/X:

Intuitively, better answers should be higher overall probability. Therefore, as it learns, the reinforcement learning algorithm is going to build up a value estimate of different sequences; if this is a better estimate of the probability-to-go than the LLM would have generated, we should have a pretty strong signal here. This avoids the RLHF problem because it’s the same model as the LLM: it’s trained on a truly massive amount of data already, and the core underlying assumption is just that the model functions better as a classifier over sequences than when making next-token predictions.
Xuandong Zhao et al. describe something similar [9] in “Learning to Reason without External Rewards,” where the model’s own internal confidence is used to guide self-improvement. And, of course, we would approximate this effect with majority voting. Similar to [1], in the paper “Can Large Reasoning Models Self-Train?" [6] the authors used a voting scheme to decide which answers to reward:
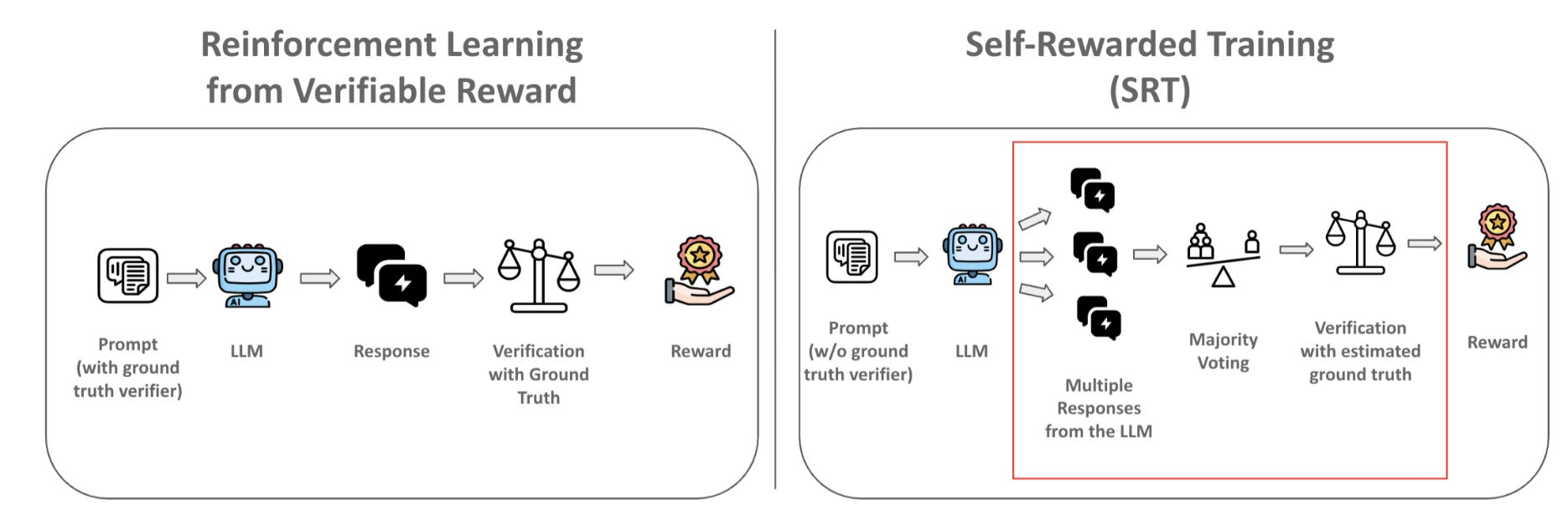
Personally, I don’t find this solution as compelling. It’s tested on math — a problem with majority voting schemes is that you need a way of matching answers — so I’m just not convinced it’s any better than RLVR. I have a similar feeling about the easy-to-hard problems in [1]: this very rigid progression seems overly rigid, and it’s not likely to generalize to unstructured problems.
Also of note are Self-Adapting Language Models (SEAL), proposed by Zwieger et al. [5]. Their goal is LLMs which can incorporate new data; they use this on, for example, a simplified version of the ARC dataset [8], which contains many challenging abstract reasoning problems, and in which you are only ever given a couple examples for a particular reasoning task. Normal in-context learning struggles with these problems; SEAL, however, has a loop wherein it can generate its own augmentations and data.
This step feels highly manually designed to me, with the method itself not needing to come up with specific augmentations or training strategies, just needing to use them. Building a broadly capable version of the model might only be possible with much more powerful base models - these experiments were only with LLaMA 3.2 1B! In addition, the method will suffer from mode collapse (honestly, all of these will), and with catastrophic forgetting.
All those caveats aside, there’s some interesting work here — and I could see many of these things working much better at scale. If SEAL was designing its self-edits based on the 671B Deepseek R1 model, how much more powerful could it be?
Recursive Improvement in AI Agents
Finally, let’s consider the possibility that we don’t really need to improve the language models at all. After all, what we care about is the ability for agents to perform tasks; if one task is, e.g. the ability to design new network architectures and run training experiments, maybe the system using the LLM could be improved on its own.
One recent work in this area was the Darwin-Godel Machine (DGM) from Sakana AI: “AI that improves itself by writing its own code.”

In this case, the agent can modify and improve its own Python codebase. It can propose new tools. It was able to improve itself from 14% to 30% success rate on Aider polyglot - a far cry from the 83% achieved by Gemini-2.5 pro and OpenAI o3-high on their own.
Of course, as foundation models improve, we might expect to see better performance, as the authors themselves state:
Furthermore, with recent FMs [foundation models] being increasingly proficient in coding, we can use FMs as meta agents to create new agents in code for ADAS, enabling novel agents to be programmed in an automated manner.
Although, in the end, the results seem a bit weak to me — there aren’t a lot of comparisons here against the “pure” LLMs, which according to the Polyglot leaderboard seem to do quite well on their own.
Other agents like Devin from Cognition have shown some impressive abilities; Refact claims their agent reaches 76.4% on the same leaderboard. These, however, are all manually designed systems — hardly the self-improving AI we’re waiting for. On that front, agents look like they have a long way to go.
Final Notes
I began with the question: “how close are we to self-improving artificial intelligence?” When I first started writing this post, I had expected the answer to be a simple “not very close at all.” This is important because I am making one crucial assumption:
If we are to see an intelligence explosion in the next 2-3 years, the research trends that lead to that explosion will be visible now.
Everything I saw when starting to research this question felt very preliminary. None of the results were mind-blowing. Some were cool ideas, but honestly quite underwhelming in the actual details. Many of the transformer-based methods seem to rely on the notion of improving LLMs’ confidence through voting or direct optimization. An exciting area, to be sure, but these types of objectives are prone to mode collapse and instability; it’s hard for me to image they’re an imminent threat.
The “problem” with trying to predict the future here, is that sometimes these methods work a lot better with scale. Methods like end-to-end learning in self driving cars, or large reasoning models, require massive investment in time, data, and compute to really “blow up.” There was nothing stopping us from building modern reasoning models sooner: it’s just that base models weren’t good enough, data and compute weren’t there.
Which is to say, if these approaches are deployed at OpenAI or Anthropic, what will happen? I cannot say. But they will be deployed there, at least in test — I am sure of that. The authors of SEAL are now at OpenAI. And people like Dario Amodei of Anthropic, and Sam Altman of OpenAI, have been warning us about self-improving AI leading to job losses for years now. I’m inclined to think that at least they believe it’s true that this will happen soon.
My personal odds we’ll see an intelligence explosion in the next few years are now at like… 5%. Which is still pretty low, but it’s a lot higher than they were last month. What do you think?
If you liked this post, please consider liking and sharing so others can find it. And if you want to see more of my random posts on AI and robotics, consider subscribing!
Errata
Why do I consider self-improvement to be ill posed? Because we don’t know how to do it yet! We don’t actually know which steps to take to get to our hypothetical self-improving system. We know some things that should work (more data, more compute), but not necessarily how to leverage them. If we’d had all the data we do now, and applied it to models as they existed in the 2000s to 2010s, it would not have worked: support vector machines and recurrent neural networks did not have the capability to scale to the capabilities of modern transformer-based architectures.
Reward learning in robotics: Interestingly, ReWIND [7] was recently proposed for reaching robot agents how to perform different tasks; it works by learning a conditional value function. Operating on the assumption that it’s easier to learn a discriminator than a generator, similar approaches might make sense for LLMs.
2025-07-08: Fixed the final figure, which is actually from a related work [10] and not the Darwin-Godel Machine.
References
[1] Lee, N., Cai, Z., Schwarzschild, A., Lee, K., & Papailiopoulos, D. (2025). Self-Improving Transformers Overcome Easy-to-Hard and Length Generalization Challenges. arXiv preprint arXiv:2502.01612.
[2] Wang, Y., Yang, Q., Zeng, Z., Ren, L., Liu, L., Peng, B., ... & Shen, Y. (2025). Reinforcement learning for reasoning in large language models with one training example. arXiv preprint arXiv:2504.20571.
[3] Shao, R., Li, S. S., Xin, R., Geng, S., Wang, Y., Oh, S., Du, S. S., Lambert, N., Min, S., Krishna, R., Tsvetkov, Y., Hajishirzi, H., Koh, P. W., & Zettlemoyer, L. (2025). Spurious rewards: Rethinking training signals in RLVR.
[4] Prabhudesai, M., Chen, L., Ippoliti, A., Fragkiadaki, K., Liu, H., & Pathak, D. (2025). Maximizing Confidence Alone Improves Reasoning. arXiv preprint arXiv:2505.22660.
[5] Zweiger, A., Pari, J., Guo, H., Akyürek, E., Kim, Y., & Agrawal, P. (2025). Self-Adapting Language Models. arXiv preprint arXiv:2506.10943.
[6] Shafayat, S., Tajwar, F., Salakhutdinov, R., Schneider, J., & Zanette, A. (2025). Can Large Reasoning Models Self-Train?. arXiv preprint arXiv:2505.21444.
[7] Zhang, J., Luo, Y., Anwar, A., Sontakke, S. A., Lim, J. J., Thomason, J., ... & Zhang, J. (2025). ReWiND: Language-Guided Rewards Teach Robot Policies without New Demonstrations. arXiv preprint arXiv:2505.10911.
[8] Chollet, F., Knoop, M., Kamradt, G., & Landers, B. (2024). Arc prize 2024: Technical report. arXiv preprint arXiv:2412.04604.
[9] Zhao, X., Kang, Z., Feng, A., Levine, S., & Song, D. (2025). Learning to reason without external rewards. arXiv preprint arXiv:2505.19590.
[10] Hu, S., Lu, C., & Clune, J. (2024). Automated design of agentic systems. arXiv preprint arXiv:2408.08435.
Great read! Just a minor thing: I think the last image should be referring to the Automated Design of Agentic Systems (ADAS): https://arxiv.org/abs/2408.08435, not the Darwin-Godel Machine.
I asked ChatGPT to weigh in on this question the day before you posted this article.
https://open.substack.com/pub/stevenscesa/p/what-does-chatgpt-v41-think-about?r=28v6pr&utm_medium=ios