
Interesting Directions in Vision-Language-Action Model Research
VLAs are an important part of the future of robotics, so what cool ideas have we seen in this space lately?


Robots need to aggregate information from a lot of different sources to make decisions about the world: namely, multiple cameras, joint encoder information, and their task specification. Models which do this are usually called Vision-Language Action models, or VLAs — something we have covered extensively on this blog in the past.
But that previous post covered the big models. Training a flagship VLA like Physical Intelligence Pi-0.5 or Figure Helix is expensive and takes a lot of data. Because of the long lead times required in labor-intensive data collection, there’s a lot less room for error - so we don’t see the fast pace of innovation that’s possible in academic research.
This time, let’s cover a wide range of different ideas. What is the future of the VLA? What ways could we improve upon the recipe outlined by PI, NVIDIA, Toyota, Google, and so many others?
But First, Why Do We Care?
There is a clear recipe for robotics over the next 2-5 years in order to deliver general-purpose autonomy. If it works, it looks like this:
Train a large base model on a very large amount of data from different robots, embodiments, from data created in simulation and the real world, in order to get it to a reasonable level of performance in basically any environment — e.g. pi 0.5.
Optionally, further improve it with fine-tuning on an application domain that you care about (i.e., all of your data in a particular class of factory or industry)
Further improve that with reinforcement learning, until your model is deployment-ready — e.g. via PLD (Probe, Learn, Distill)
In this post, I’d mostly like to talk about the “base model” — the large model that can do everything in the world at least a little bit okay. This is generally what we would call a Vision-Language Action models, and they’re something I’ve written about before:
Vision-Language-Action Models and the Search for a Generalist Robot Policy

At the UPenn GRASP lab, researchers do something that is still shockingly rare: they download a state of the art robot policy and just used it for a while.
Interesting Research Directions
Now, as we discussed in that previous blog post, training VLAs is very difficult, and getting good generalization is very difficult, and so there’s a lot of interesting research going on which aims to do one of several things:
Improve the ability of VLAs to use data from different embodiments, such as unlabeled egocentric human video
Improve their generality and robustness, often through the use of 3D priors
Incorporate tactile or other sensory information
Improving usability through fine-tuning or in-context learning
This post is a bit of a round-up of various VLA papers I have seen that don’t cleanly fit into some other post I have planned to write, but that I found interesting. In this blog post, I’ll go over a few research questions, associated papers, and leave a few notes on why I thought each one was interesting.
If you find this interesting, or would like to suggest a paper that I missed for the next roundup, please click the appropriate button below.
Including Tactile and Force Data

Tactile sensors allow robots to have a “sense of touch,” something that’s important both for precise force-controlled manipulation and for robustness when handling unseen objects and environments. I’ve written a longer post on this before:

Of course, your vanilla vision-language-action model does not have any of this information, partly because there are so many open questions about how to represent and store tactile information.
In this work, they started with a pretrained VLM (Gemma), as is common in VLA research and development, and provide as additional input a learned encoding of the tactile sensor data. In addition, they trained a specific tactile action expert for predicting robot actions. Honestly, I’m somewhat surprised this “naive” approach of initializing from a pretrained Gemma backbone worked, but they show a pretty impressive improvement on a USB drive insertion task.
In the future, I think there’s been some promising work on encoding tactile information into Transformer models, most recently [3]:
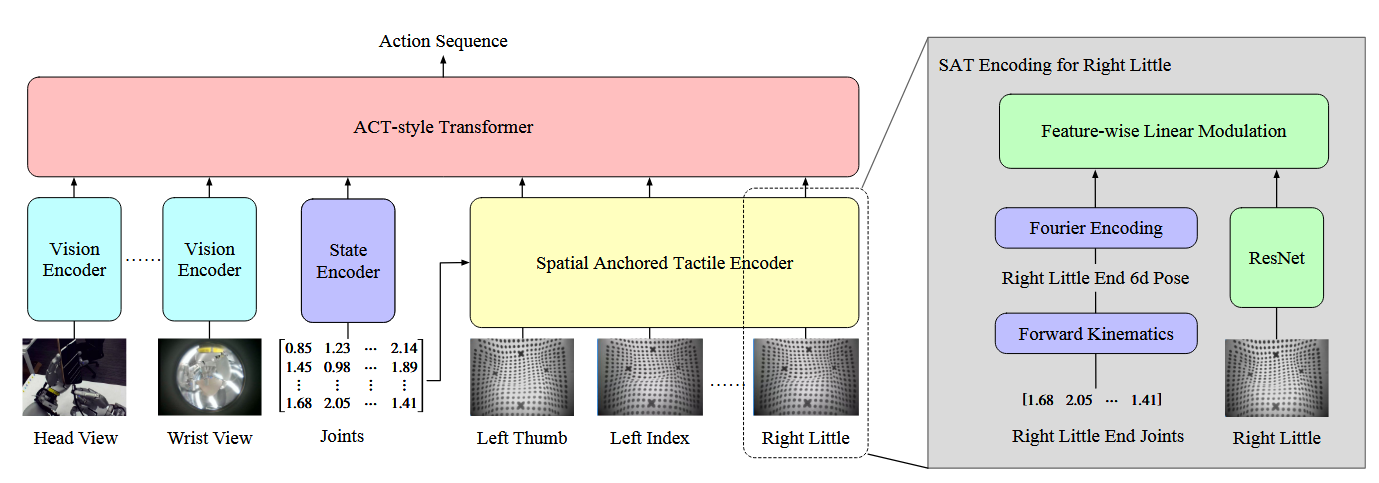
Spatially encoding tactile information seems to be potentially much more general than learning an MLP, simply because it should transfer and generalize much better. While this particular paper isn’t a VLA, it’s easy to see how it could be included into a VLA in the future.
In Context Learning with VLAs
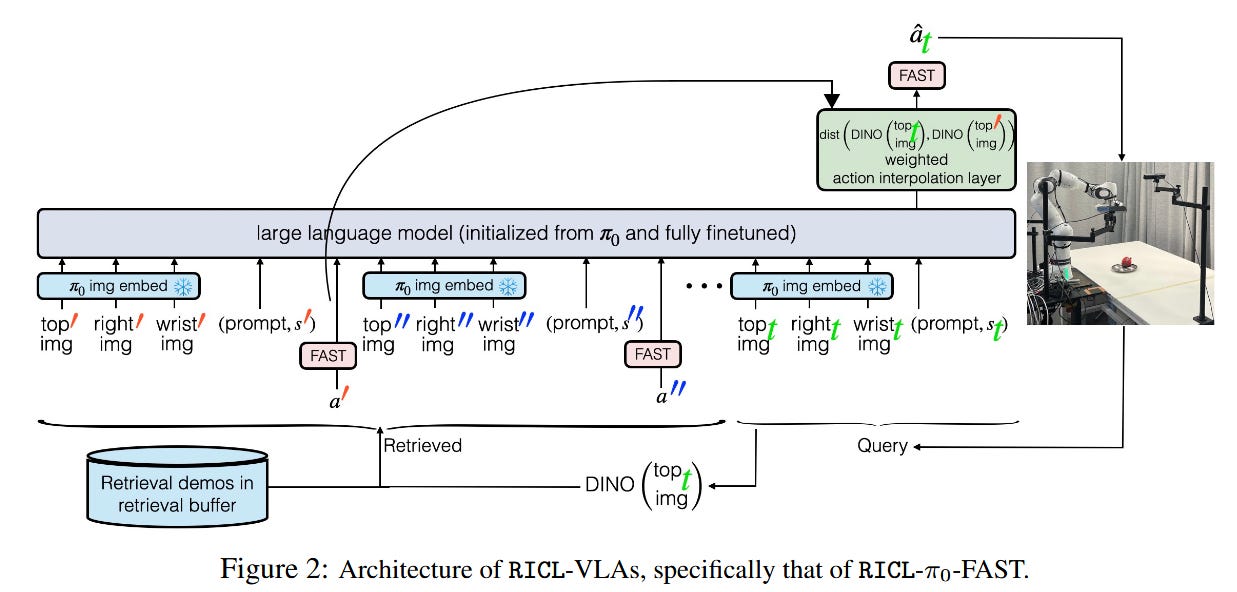
For many real-world tasks with LLMs, we use in-context learning. This has been applied to robotics before, but not usually in the context of a general-purpose VLA. Researchers from UPenn retrained π₀-FAST to perform what they call Robot In-Context Learning (RICL) [2], which means that you can provide 10-20 demonstrations to improve policy performance without retraining or fine tuning the model. This allows for improved performance on previously unseen environments and objects.
Unifying VLAs and World Models
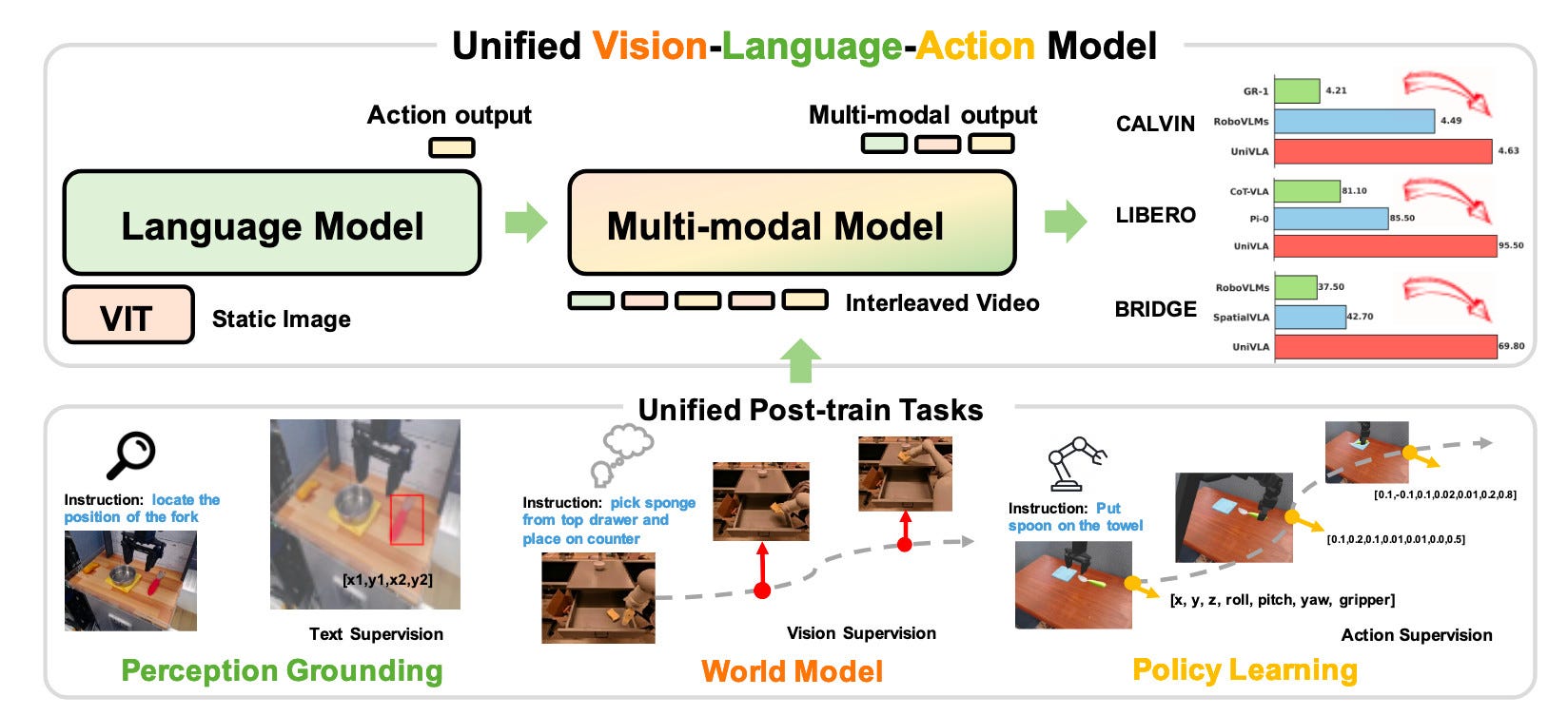
“World models” are action-conditioned video prediction models that are an active and very exciting research area, which I have covered before on this blog.
UniVLA [4] is an interesting fusion of this with the core concept of a vision-language-action model. It represents actions, language, and images all as tokens within a single unified framework — which means that it can also do more downstream tasks like predicting the future as a world model.
This is potentially exciting because it gives us more ways to learn these crucial foundation models on a wider variety of data — potentially leading to less data wastage during the expensive and time-consuming process of scaling up robot data.
Including Spatial Information in VLAs

Including spatial information is one way to make robots more data efficient, more reliable, and easier to train and deploy. But most VLAs don’t use spatial information, because while it scales better, collecting the data is harder and the sensor requirements are more stringent.
But there are still a few that have looked at this problem. OG-VLA [5] builds on a line of work from NVIDIA and renders multiple views to generate 3d keypoint frames. This type of approach achieves state-of-the-art generalization to unseen pick-and-place tasks.
MolmoAct[6] handled this slightly differently, forcing the model to capture spatial information by asking it to predict depth tokens as a sort of “reasoning” step. You can check out our recent RoboPapers episode on that one here:

Reinforcement Learning with VLAs
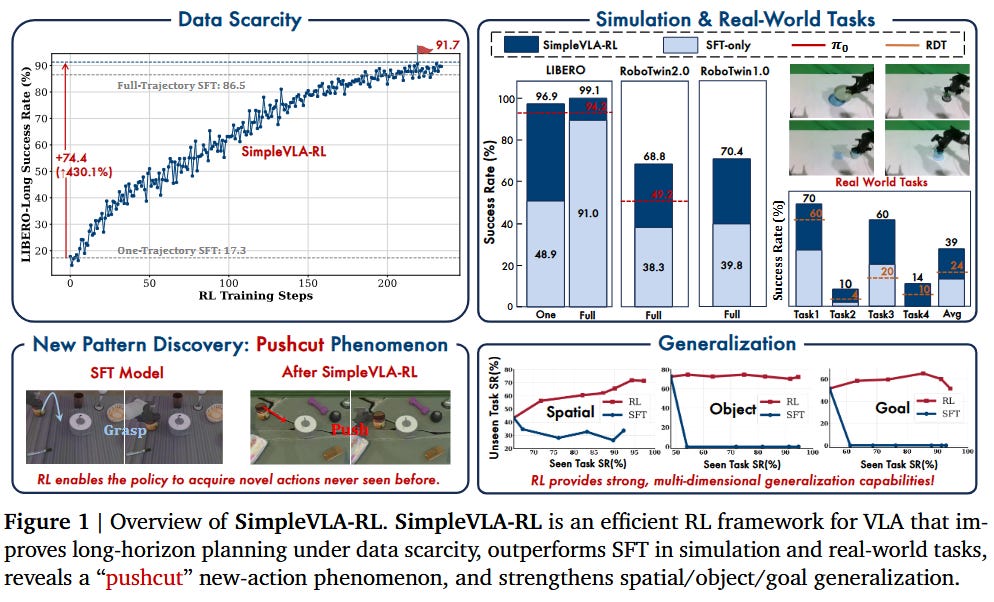
As mentioned above, reinforcement learning seems to be a key part of progress for LLMs, beginning with OpenAI o1 and Deepseek R1. It makes them much better at code and math, among other things, and helps support long horizon reasoning.
The same logic probably applies to robotics; so we’ve seen a few works try to combine Vision-Language-Action models with reinforcement learning. SimpleVLA-RL [7] shows an example of how: they start with OpenVLA-OFT, a fine-tuned and improved version of OpenVLA, and use the GRPO algorithm to update the VLA.
Importantly, they can use sparse rewards because they’re training based on a VLA that can already sort of accomplish the task. This is important because reward function engineering is, well, kind of terrible. For more on that, you can look at this previous post of mine on reinforcement learning and its limitations:

Another very cool work along these lines is Probe, Learn, Distill [8] from the NVIDIA GEAR lab and friends. PLD uses residual policy learning, meaning that instead of modifying the underlying VLA it learns a set of additional deltas on top of the VLA to improve success rates.
Final Thoughts
This is sort of a random selection of papers that I thought were interesting directions and ideas; it is by no means a comprehensive overview of any of these different sub-areas of VLA research.
Overall, I think vision-language-action models are a key part of the future, and there’s a lot of ground to cover. I’ve given an overview of the area as a whole, the general recipe, and the major players before here:
Vision-Language-Action Models and the Search for a Generalist Robot Policy
At the UPenn GRASP lab, researchers do something that is still shockingly rare: they download a state of the art robot policy and just used it for a while.
It’s an exciting time, and I am sure I will do more papers like this in the future. Leave a comment with thoughts or other papers worth covering in an overview like this one.
References
[1] Huang, J., Wang, S., Lin, F., Hu, Y., Wen, C., & Gao, Y. (2025). Tactile-VLA: Unlocking vision-language-action model’s physical knowledge for tactile generalization (arXiv:2507.09160). arXiv. https://doi.org/10.48550/arXiv.2507.09160
[2] Sridhar, K., Dutta, S., Jayaraman, D., & Lee, I. (2025). RICL: Adding in-context adaptability to pre-trained vision-language-action models. In J. Lim, S. Song, & H.-W. Park (Eds.), Proceedings of The 9th Conference on Robot Learning (Vol. 305, pp. 5022–5038). Proceedings of Machine Learning Research. https://proceedings.mlr.press/v305/sridhar25a.html
[3] Huang, J., Ye, Y., Gong, Y., Zhu, X., Gao, Y., & Zhang, K. (2025). Spatially-anchored Tactile Awareness for Robust Dexterous Manipulation. arXiv preprint arXiv:2510.14647.
[4] Wang, Y., Li, X., Wang, W., Zhang, J., Li, Y., Chen, Y., Wang, X., & Zhang, Z. (2025). Unified Vision-Language-Action Model (arXiv:2506.19850). arXiv. https://doi.org/10.48550/arXiv.2506.19850
[5] Singh, I., Goyal, A., Birchfield, S., Fox, D., Garg, A., & Blukis, V. (2025). OG-VLA: 3D-Aware Vision Language Action Model via Orthographic Image Generation (arXiv:2506.01196). arXiv. https://doi.org/10.48550/arXiv.2506.01196
[6] Lee, J., Duan, J., Fang, H., Deng, Y., Liu, S., Li, B., Fang, B., Zhang, J., Wang, Y. R., Lee, S., Han, W., Pumacay, W., Wu, A., Hendrix, R., Farley, K., VanderBilt, E., Farhadi, A., Fox, D., & Krishna, R. (2025). MolmoAct: Action Reasoning Models that can Reason in Space (arXiv:2508.07917). arXiv. https://doi.org/10.48550/arXiv.2508.07917
[7] Li, H., Zuo, Y., Yu, J., Zhang, Y., Yang, Z., Zhang, K., Zhu, X., Zhang, Y., Chen, T., Cui, G., Wang, D., Luo, D., Fan, Y., Sun, Y., Zeng, J., Pang, J., Zhang, S., Wang, Y., Mu, Y., ... Ding, N. (2025). SimpleVLA-RL: Scaling VLA Training via Reinforcement Learning (arXiv:2507.08643). arXiv. https://doi.org/10.48550/arXiv.2507.08643
[8] Xiao, W., Lin, H., Peng, A., Xue, H., He, T., Xie, Y., Hu, F., Wu, J., Luo, Z., Fan, L., Shi, G., & Zhu, Y. (2025). Probe, Learn, Distill: Self-Improving Vision-Language-Action Models with Data Generation via Residual RL (arXiv:2509.07090). arXiv. https://doi.org/10.48550/arXiv.2509.07090
In my opinion, VLAs research is extremely empirical compared to many other directions.
Simulation like Libero is no more statistically meaningful benchmark as we can overfit to ~99% easily right now. Urgent things are: 1) Create new benchmark in sim 2) Show the real world experiments actually improve in behaviors 3) Do more ablation study on data recipe / improvement.
Without above, we can hardly tell if it is the new incremental components work, or just the base model is strong enough to solve the problem.