


Self-Driving Taxis Scale Up
The upcoming launch of self driving taxi services from Tesla and Wayve show how predictions about the industry are finally coming true


Self-driving car company Wayve is doing something big: for the first time they will deploy an autonomous taxi service in London, according to CEO Alex Kendall on X. With this announcement, they join Tesla and Waymo as companies with immanently deployed self-driving car fleets. All this on the heels of raising a $1.05 billion Series C in May of last year. They’ll be partnering with Uber to roll out their service.
Self driving cars are in a lot of ways the first “real” robots: they’re expected to go out, every day, in the real world and perform work in unstructured environments, hour after hour and day after day. This makes the self-driving car industry an important place to watch if you want to understand how other types of robots could scale.
And as always, if interested, you can subscribe for more posts like this:
Rapid Progress in Self Driving Capabilities
From an outside perspective, the self-driving car field felt a bit sleepy in the first half of the 2020s. There were self-driving vehicles being tested on the streets of San Francisco by Cruise (RIP) and by Waymo.
Waymo’s trajectory in San Francisco has been truly incredible. Not only is Waymo clearly safer than human drivers, but in May 2025, it passed five million rides across its operating cities (San Francisco, Los Angeles, Phoenix, and Austin).

No one else has yet managed this kind of explosive growth in the robotaxi service, and it shows that Waymo minimally has a recipe that works very well for the sunny cities of the American southwest and west coast.
At the same time, Tesla has been steadily gaining ground. While not yet at Waymo’s etremely high success rate, Tesla has been catching up, with most rides using their Autopilot now requiring 0-1 interventions, and over 90% of interventions not being critical (so, not dangerous), according to the Tesla Community Tracker.
And that’s completely aside from their forthcoming Robotaxi service, whose vehicles were recently sighted around Austin:

Tesla intends to start their Robotaxi service small at first. And when it comes to running a taxi service, they’re notably behind Waymo — but, of course, they can build their cars at scale in-house, and their vehicles are much cheaper per unit than Waymo’s. Once they prove out their robotaxi program, it might be a relatively fast ramp-up to deploying large numbers of taxis in American cities.
What Technologies are Enabling This?
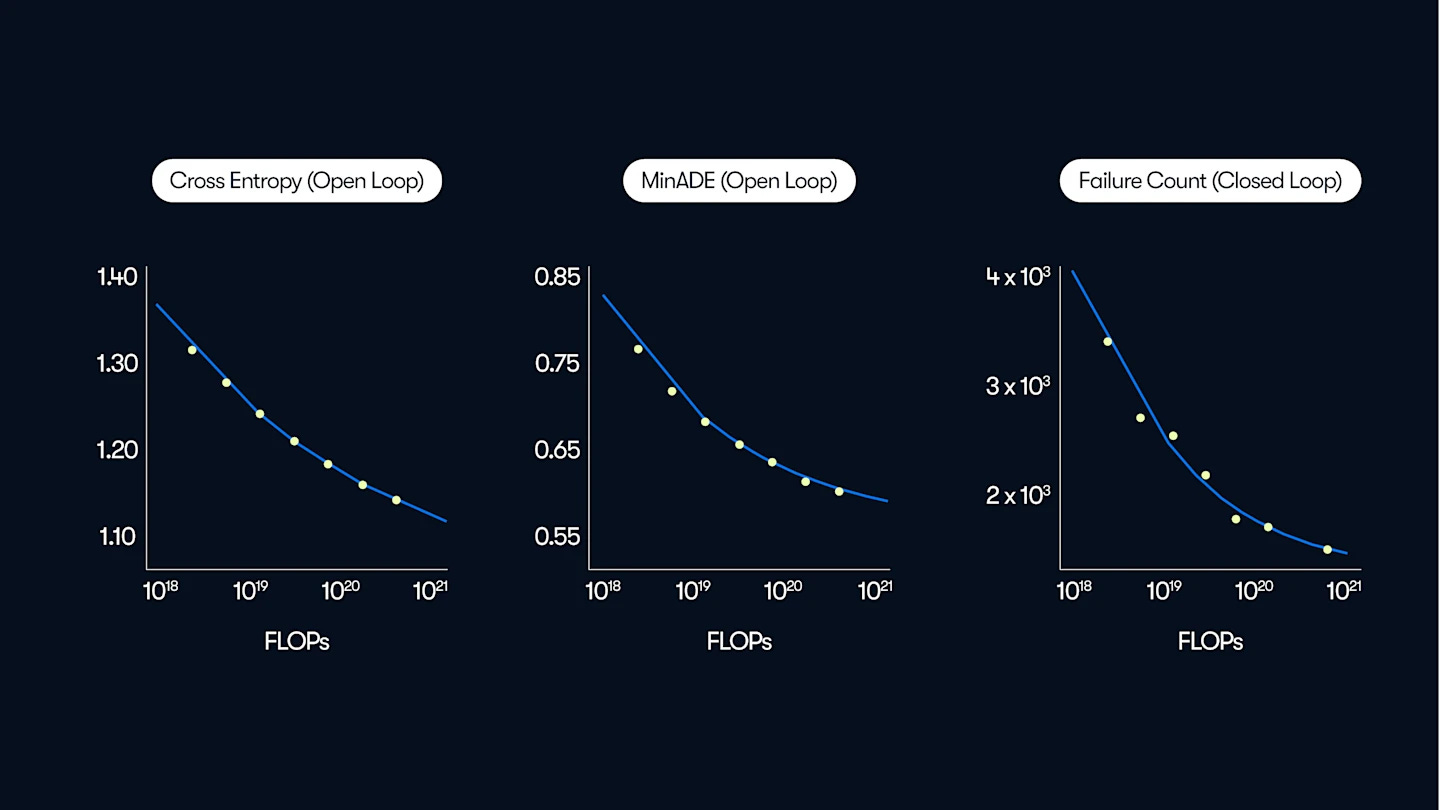
In short, deep learning is ready for the real world.
As described in a recent blog post by Waymo, it turns out that the core machine learning tasks for self-driving cars — trajectory prediction and motion forecasting — obey the same scaling laws as, well, pretty much everything else. You can turn data and compute into performance improvements.
This is valuable because it provides a clear, scalable route forward: rather than needing human engineering to overcome every last failure case, something which has never scaled particularly well, we can collect a more and more expansive set of driving data which captures all relevant situations.
How are self-driving car companies getting this data? Well, in part, from driving. Tesla FSD users have driven over 1.3 billion miles. Increasingly, though, they use simulation.

Waymo has driven 20+ billion miles in simulation, compared to 20+ million miles in the real world. They’ve pioneered techniques like Block-NeRF to neurally render large scenes, letting them construct photorealistic simulations from data. Wayve, famously, has been exploring techniques like their GAIA-1 generative world model to mass-produce synthetic driving data.
And Tesla, too, uses simulation to a large extent to improve their Full Self Driving system. Elon Musk has repeatedly emphasized the importance of simulation, having claimed in the past that Tesla’s simulation and video generation capabilities were the “best in the world.”
Why Now?
One of the interesting stories around the Deepseek R1 release was actually how non-novel it was: many had tried reinforcement learning on top of large language models before. The same with Meta’s ill-fated launch of Galactica, a large language model that barely preceeded ChatGPT and only lasted three days online.
What changed to make Deepseek R1 or ChatGPT a success wasn’t some clever algorithmic breakthrough. In Deepseek’s case, it was likely that the base models upon which R1 was trained were finally good enough. ChatGPT was trained on a better, broader set of data, building off of a larger and more coherent effort by OpenAI instead of scattered individual research projects. In short, the differentiators were timing and good engineering.
Timing is important because all the pieces are in place: supply chains established, Waymo has “proved out” the feasability in San Francisco, and regulatory hurdles aren’t looking so fearsome.
And, of course, all of these companies finally have the data and compute they need. Because all of the rules that govern human driving are nearly impossible to code up by hand, and learning, unlike human effort, scales really well.
Now, people like to say that Waymo’s approach is less end-to-end than, say, Tesla’s, and this seems true but incomplete. Waymo is no stranger to end-to-end neural networks for self-driving vehicles: see Waymo’s EMMA, for example, a large-scale multimodal model tailored for self-driving tasks like motion planning and 3d reasoning.
Final Thoughts
During my exit from self-driving, to go work at NVIDIA in robot manipulation, I told a professor that I thought self-driving cars were 5-10 years away, and probably wouldn’t be real until the mid-2020s. This seems to have been on the money.
In my life, I’ve put a lot of thought into scaling robot learning. Without a doubt, self driving cars are the most prominent example of how one can scale robot learning to a massive degree. They’ve now been in operation for years; they have massive amounts of data; and, clearly, they actually work in the real world.
So, what can we learn:
Large amounts of data and compute are essential for general robotics.
Synthetic data is a part of the answer: we see Waymo with Block-NeRF, Wayve with GAIA-1, etc.
Real-world data is also crucial, as is deploying robots at scale; this starts the “feedback loop” to transform robots into more general agents.
All of this seems very in line with my previous post on how to get the data we need for a “robot GPT,” which you can check out here:
How can we get enough data to train a robot GPT?

It’s no secret that large language models are trained on massive amounts of data - many trillions of tokens. Even the largest robot datasets are quite far from this; in a year, Physical Intelligence collected about 10,000 hours worth of robot data to train their first foundation model, PI0. This is something Andra Keay
I expect to see this same recipe play out in robot manipulation.
If you’d like some more context on the self-driving car industry, you can check out my post from December of last year, around the moment when we lost Cruise:
Self Driving Cars are At A Transition Point

GM Cruise is no longer building a robotaxi, as of this past week. This is a huge disappointment (although not necessarily a surprise), as they were long one of the apparent leaders in the race to build a robotaxi business, and their cars were at one point a pretty common sight around San Francisco.
And of course, if you like this sort of content, please consider subscribing/sharing/liking this post, and leave a comment with your thoughts.
The language model hype shielding the robotics and self-driving industries from focal point levels of hype is wonderful for incremental rollouts. So much progress. I love Waymo.
You know that Tesla's "robotaxi" pilot is just remote safety drivers, right? It is going to be functionally no different from the current technology. The only difference is the "hands always on the wheel ready to takeover" is occurring remotely.