
What Do Robotics Leaderboards Tell Us About The State of Robot Learning?
There remains no chatbot arena for robotics


It’s really hard to tell which robot policies are better than others, and who is actually making the most progress towards embodied general intelligence. I’ve written about robotics evaluation many times before, but this time I wanted to talk about leaderboards, as inspired by a thread on X.
There are many benchmarks, but few evolving leaderboards. PolarRiS, for example, is a great tool for benchmarking which correlates well with real-world performance, but it isn’t a live leaderboard in the same way — the authors do not update it, and the set of entrants is closed to the ones they chose at paper writing time.
Instead, let’s look at what public artifacts we have over time, from people who have been updating results over time, and see if we can identify any trends in robot learning.
Why This is a Hard Problem
There are two challenges here:
Running a benchmark is expensive
You need buy-in, which means community excitement as well as a feeling of progress (the benchmark must be hard but not too hard; real but not too real)
I actually briefly ran a robotics competition for open-vocabulary mobile manipulation (OVMM). There are a few problems here which make this uniquely hard for robotics compared to computer vision leaderboards (even something like the chatbot arena).
First, it’s costly to run a leaderboard like this, especially if your main audience is academics. Unlike LLMs, robot evaluation is costly: you need either large-scale simulation, or actual robot hardware, neither of which is cheap. Robot hardware in the real world will also incur resetting costs which do not exist for a language or image-based benchmark.
Another issue we’ll have to contend with: once a benchmark becomes widely accepted, it loses some of its value because people start to cheat.
Benchmark Hacking
Another big issue is benchmark hacking. We have seen this before with major LLMs like Meta’s Llama 4, but it’s rarer in robotics, partly because our benchmarks aren’t of widely accepted value like Chatbot Arena is/was.
This appears to have changed:

Read the thread from Pranav Atreya on X for more info. RoboArena works by volunteers evaluating pairs of policies; some teams were volunteering to assess policies, but often not completing all the evaluations they were assigned.
You’ll notice that now they’ve added indicators to their leaderboard for which models are low-sample:
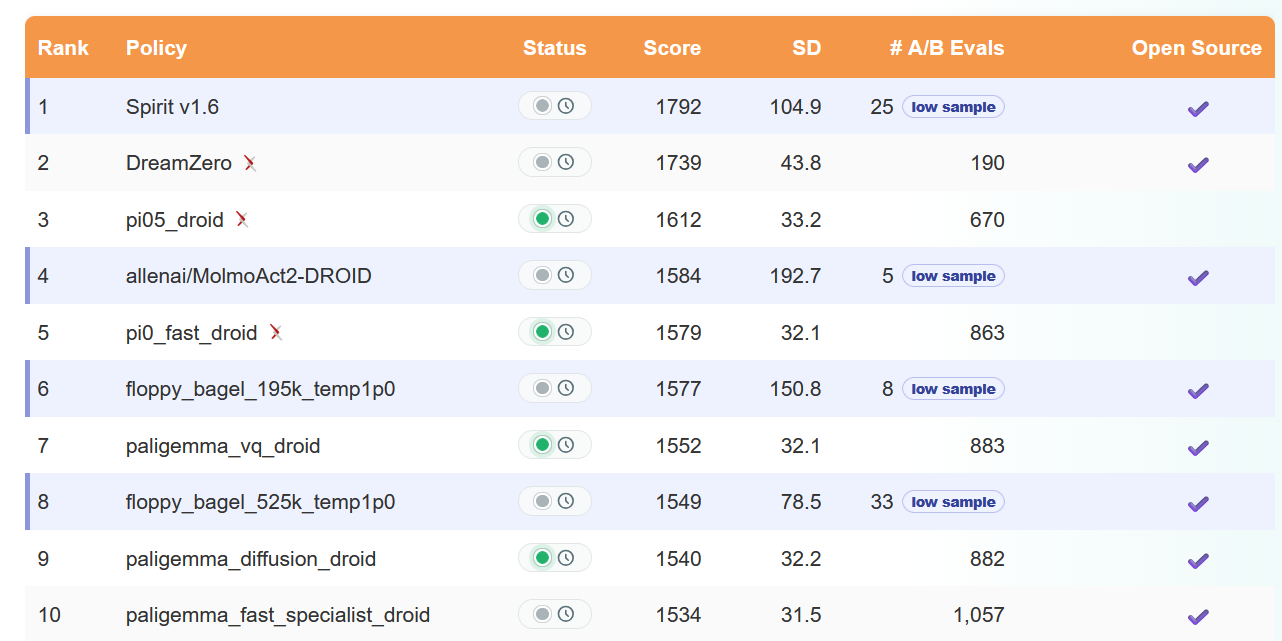
Spirit, currently vying for top spot but with low confidence, is a fast-growing Chinese AI startup. Their VLA (Vision Language Action model - basically a generalist robot policy) is in fact open source, and you can find it on Github. For a primer on VLAs, check out my previous blog post on the topic.
My Own Attempt: The HomeRobot Benchmark

When I was at Meta we wanted to build a real-world robotics benchmark for pick and place. This is one of my favorite tasks still, and one that I think the robotics community remains fairly bad at because dexterity and task-specific work has overtaken it in focus.
Here’s the problem: I want a robot which can help me out in my home. That means I need to be able to tell it to pick up any object, and move it to any other location. As a hint we also gave it an idea of where the object could be found (sofa, chair, etc), as with low-resolution cameras maybe you cannot see a small object from across the room, and in a large house this will increase problem size tremendously.
In our case, we split this between a simulation-only leaderboard, exploring a bunch of different simulated homes (in the Habitat simulation), and a real-world setting in a specific apartment built by Meta for the purpose.
The simulation component was implemented on EvalAI. Basically: submit a docker image containing your code, it gets executed by us, and we maintain full control of the test environment. This is a bit different from most modern leaderboards, which emphatically do not allow for on-site code execution — but of course it also dramatically affects hosting costs.
In the end, the experiment was a middling success; roughly 60 teams submitted, we briefly evaluated three of these in the real world. We learned a lot though.
It’s very hard to strike a balance between “too hard” and “too easy.” OVMM was a case that was actually pretty hard for learning-based methods, and in fact our winning solution in sim and real was a model-based method that merely leveraged open-vocabulary vision.
A lot of the time was spent chasing down simulator bugs or tweaking RL environments to make sure they trained properly — in order to give those using the environments something to actually work with, and make sure the environment actually transferred to the real world.
Another note is that the $25,000 Hello Robot Stretch was probably still too expensive. Today I would probably want to use something like XLERobot or BracketBot — at less than 1/10 the price, everyone could buy one and use it. This would also make it more important for us to set up “home testing” instructions, codifying the rules we could use so people could scatter objects around their own labs to get a good signal about how well they would do.
Three Leaderboards
But enough about that. Mobile robotics benchmarks are particularly difficult, as they just take up so much time, to build and to evaluate. Most of the excitement today is around robot dexterity — robots manipulating objects.
Let’s look at three interesting leaderboards for robotics models that have all been updated recently:
RoboLab-120: a simulation-based benchmark with experiments run by NVIDIA staff (leaderboard, code)
RoboArena: a distributed, simulation-based robotics leaderboard where experiments are run in reality (leaderboard, RoboPapers episode, code)
MolmoSpaces: an open-source platform for robotics develeopment, supporting multiple simulations and training methods. Technically this one is a mobile robot leaderboard, with a range of different tasks (leaderboard, Robopapers episode, code)
What do we see when we compare them?
RoboLab-120

Recently, RoboLab-120’s authors added Cosmos3-Nano-Policy to the leaderboards. This pushed down pi-0.5 and DreamZero, previously the top two previous policies.
RoboLab is a procedurally generated environment simulation based on pick-and-place tasks. Most of its benchmark entrants are VLAs. You can check out the list of example tasks here: they are dominated by pick and place, all in simulation, and run in different environments.
Some examples:
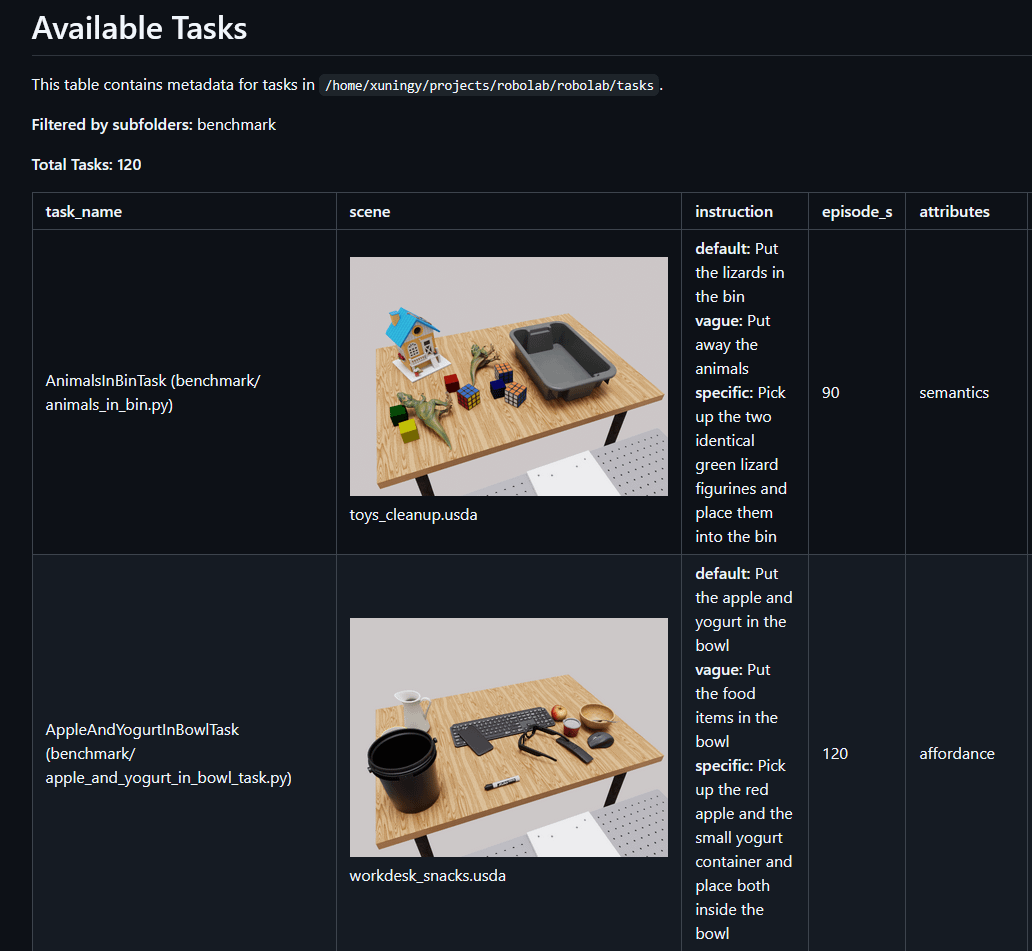
The environment leaderboard is dominated largely by VLAs, and all evaluations are run in-house. This is in many ways the gold standard for a benchmark, because you can’t just submit your own run (impossible to game, as happened briefly to RoboArena), but also means that the number of individual models is very limited — no Spirit VLA, for example.
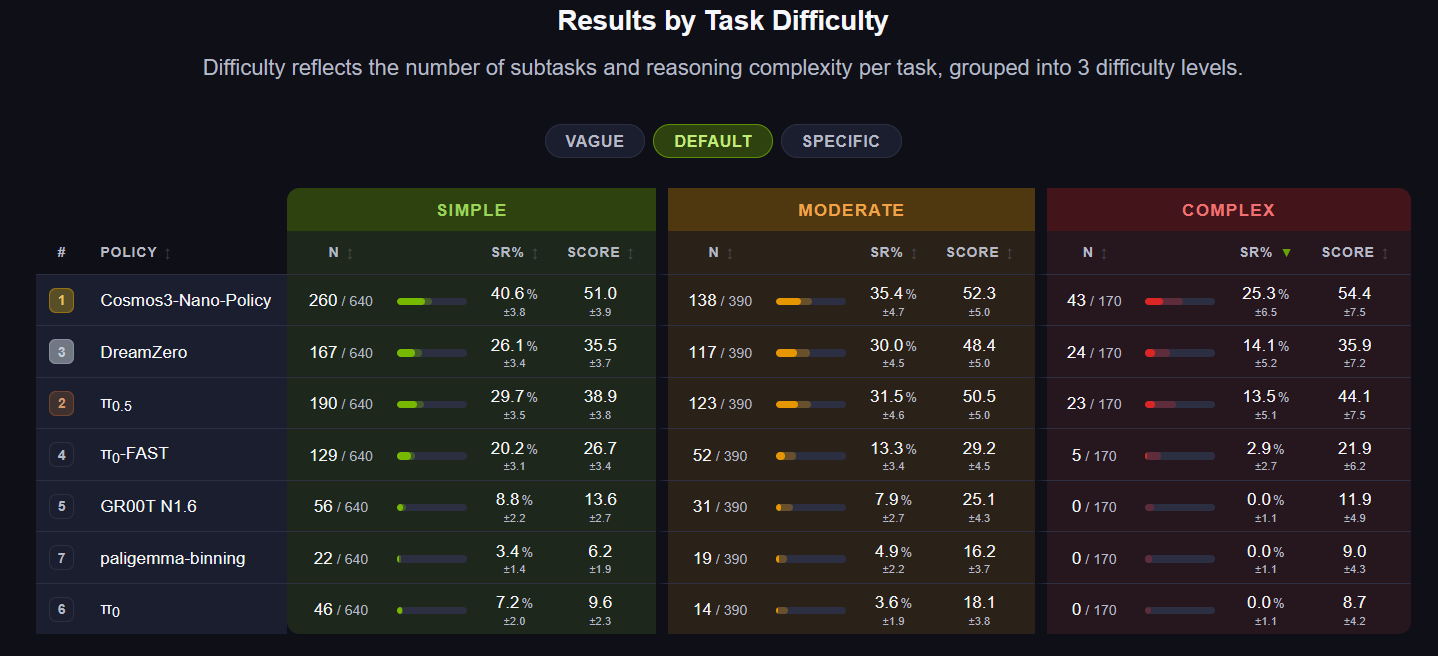
The breakdown is interesting too. We see the newest NVIDIA model at the top, perhaps unsurprising for an in-house NVIDIA benchmark. The old pi-0.5 is second place, unless you rank for complex tasks only — in which case DreamZero comes in second.
RoboArena
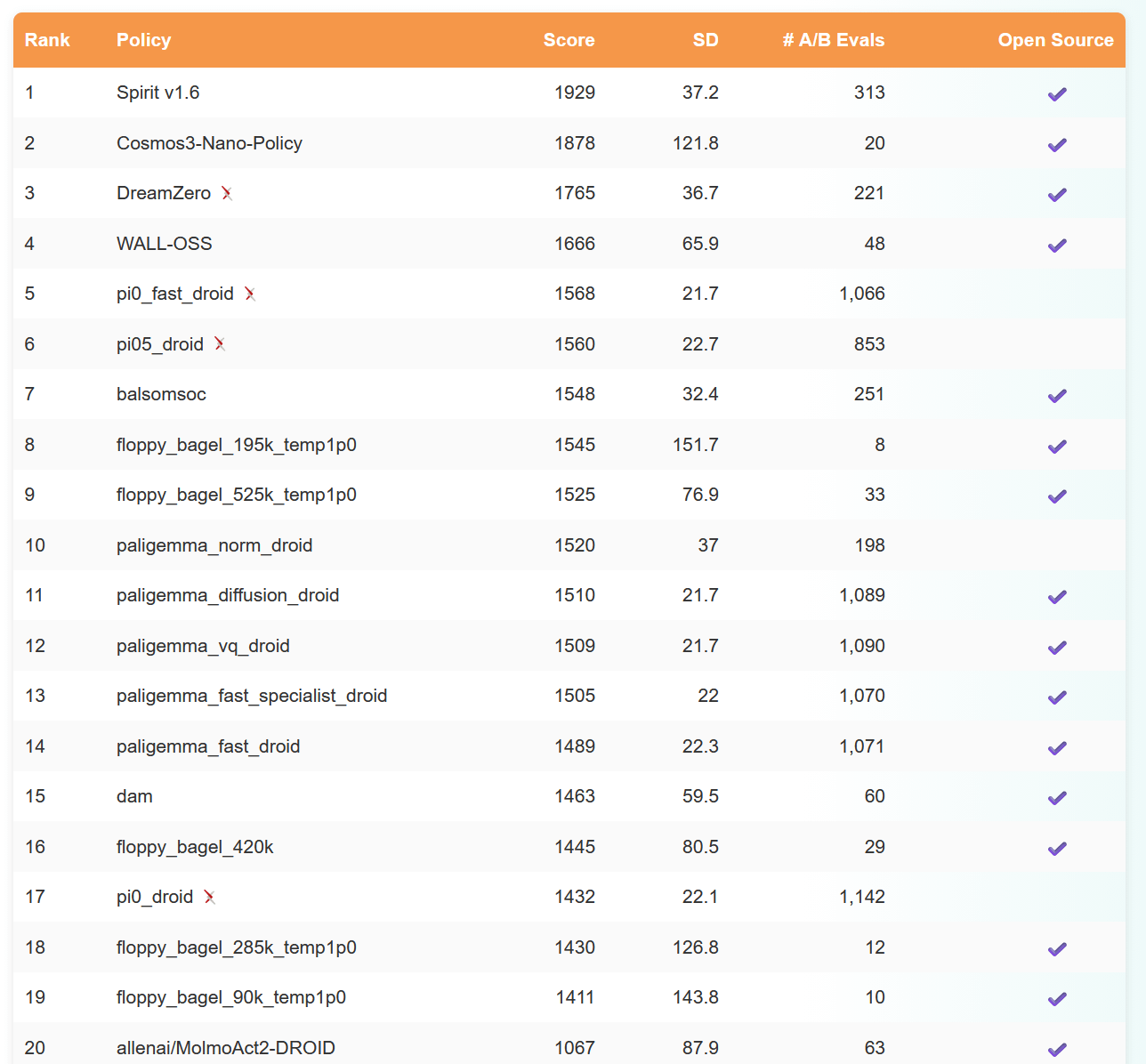
We can see several world action models at the top (DreamZero for example), and the Spirit VLA mentioned above. There’s a much wider range of policies here, though the “confidence” can be a lot lower - there are so many more policies being submitted, and so many fewer potential evaluators.
If you have not seen it, this image from the website is a good indicator of what the policy evaluation environment looks like:

Basically, it is a benchmark of a single Franka arm performing various tasks, again largely pick and place. It’s another leaderboard that is completely dominated by VLAs and World Action Models, with Spirit,
MolmoSpaces
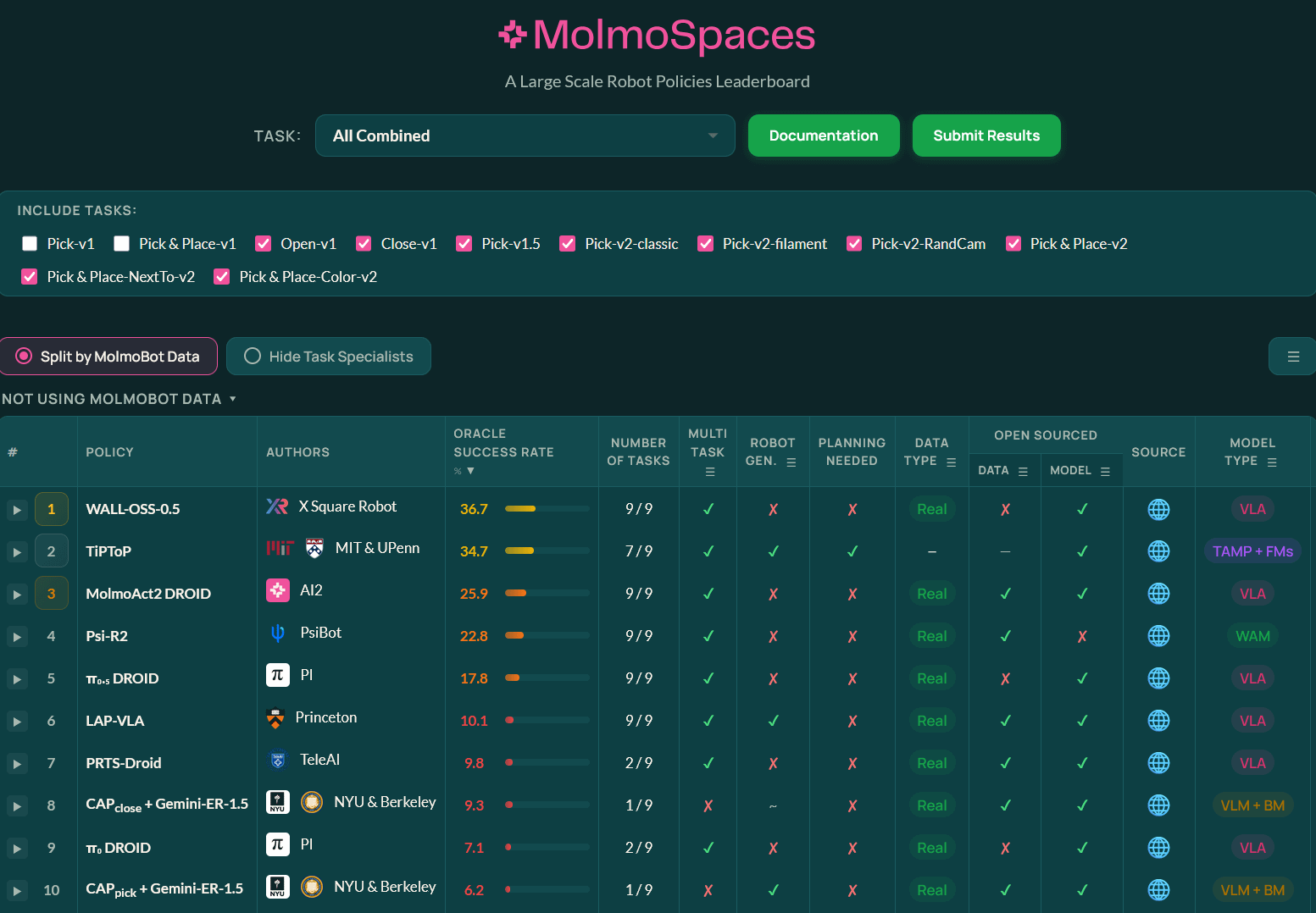
This is probably the most different experiment. MolmoSpaces is large and can involve mobile robots. While AI2 provides data, it’s not going to be as well studied as the Droid dataset. Correspondingly, we see a very different set of benchmark results here — some hybrid methods, including TiPToP, a task and motion planning-based system that leverages foundation models.

The wider range of tasks makes this benchmark more interesting, but it’s a pure simulation benchmark with lower-quality rendering.
Final Thoughts
There are many other benchmarks out there. I’ve written at length about evaluating robot policies before, and won’t go into that in more detail:
But let’s look at what the top entries here actually are. When it comes to pick and place tasks, there’s not a strong consensus — the ordering of the top models seems in flux. Compared to LLMs, though, it seems older models (especially pi-0.5) have a lot more staying power. It’s also just possible that benchmarks like RoboArena are easier to saturate - that we need complex, and more challenging, benchmarks with associated resources for verification.
So, my takeaway: we still really don’t know what is the best here, and there are no clear winners who just dominate all available benchmarks. Anyone could still “win” in robotics. We see new players (Spirit) appearing at the top of established leaderboards; we also see a surprising stickiness for some older policies.
Part of that last stickiness is almost certainly data — pi-0.5 was trained on tens of thousands of hours of high-quality real robot data, which many newer entrants have not yet managed to collect. This will put them ahead, at least until the large data collection industry can be leveraged to bolster their performance.
Let me know what you think; and what you think the future robotics leaderboards should actually look like.