
Will World Models Allow Robots to Think?
A brief review of the technology powering a new generation of intelligent robots

Even if we should be freaking out about AI, intelligence specifically in robots still has a long way to go — it can take weeks to deploy a robot for a new task. On the other hand, video generation has gotten insanely good recently: Veo 3 from Google and Seedance 2.0 from ByteDance seem likely to change the way Hollywood works forever.
Perhaps as a result of this incredible jump in capabilities, world models — which is to say, video-predictive model for robot tasks — are one of the most exciting trends in robotics right now. They show advanced generalization capabilities, can execute open-ended tasks, and provide an effective way to leverage large amounts of internet data to learn “priors” about how the robot should interact with the world, thus providing an effective way to close the robot data gap.
I’ve written about world models before, so think of this post as an update — looking at the developments over the last few months and a couple novel ways of employing these models, as well as some trends that have developed.
If you like this blog or these kinds of posts, please like, subscribe, and share:
Types of World Models
I’ll go over a few different types of world models that people look at. Note that I am to some extent using my own terminology here; terms like “world model” and “world action model” get used all the time for all sorts of things, so I’m going to give you three different ways of setting up the problem. There are, of course, tons of types and subtypes within each.
Action-conditioned World Models, like V-JEPA 2 [1], which predict future states based on an action vector. These are the most theoretically justified, and are the “model” in “model-based reinforcement learning” — a very well-studied but still nascent area of robot learning.
These (very, very roughly) take the form:
where f is the world model, x are state observations, a are actions, and x’ is the predicted future state sequence (image or video). They are the “classic” formulation of the problem, and have been famously championed by Yann LeCun. Other great examples are Dreamer v4 [2], which learned a “simulation” of minecraft and was able to train policies within that world model; and RISE [3], which is a recent paper that learns a “local” action-conditioned world model and uses it for reinforcement learning.
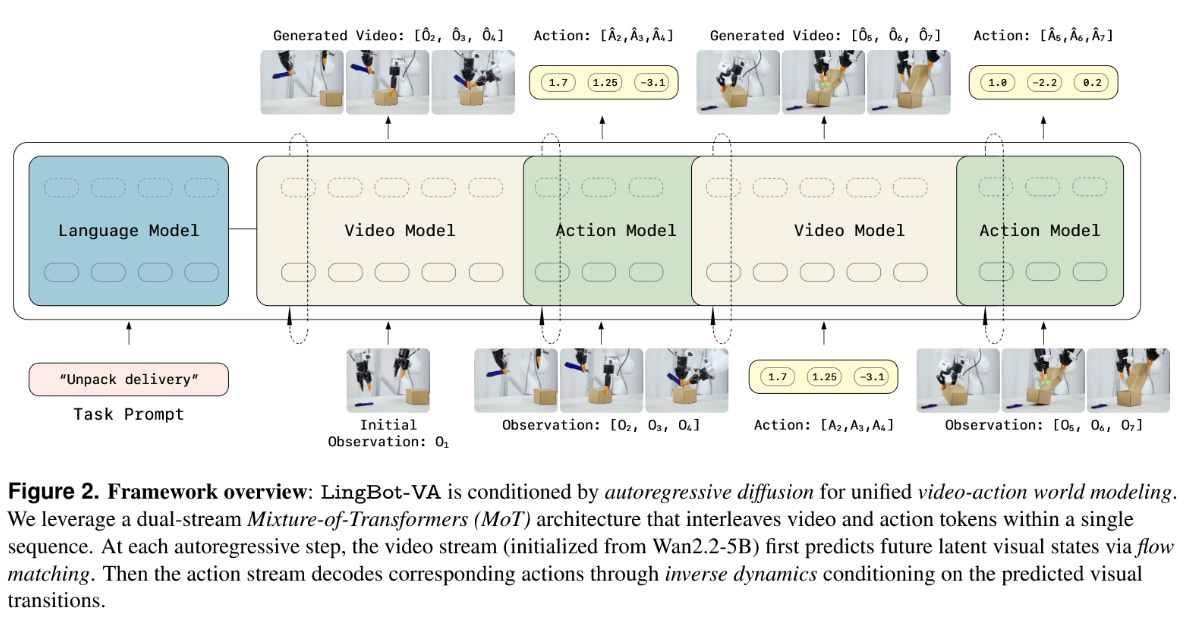
Next, there are Video World Models, which work by generating a video first, and then work backwards using an “inverse dynamics model” to recover robot actions — DreamGen from the NVIDIA GEAR Lab is an example [4], as is the most recent 1x World Model, and the LingBot VA model from RobbyAnt [5].
These have the advantage of most directly being able to leverage large-scale video data, as they do not need actions at all to train the world model, but instead recover actions from this “inverse dynamics model” g which can be trained on far less data:
Finally, joint World Action Models (WAMs) are policies which predict both video and action jointly -- DreamZero is an example [6], as is Fast WAM [7]. While the term has been used many different ways, I’ll use it here to mean a joint prediction, indicating that it learns both how the world evolves and what actions the robot is taking together:
These models seem to generalize better than alternatives, as explored in the paper “Do World Action Models Generalize Better Than VLAs?” by Zhang et al [8].
Separately, there is also the question of 2D vs. 3D. There are also 3D generative world models - which create a 3D scene, such as PointWorld [9] or Marble from World Labs. This is very broad category, deserving of its own post in the future.
Background: Planning For Robots, or: Why Do We Care About This?

Planning for robots is a field with a long history, dating back over 50 years. People have been using robots to solve complex, long-horizon problems forever. The issue is that these always rely on models of the world, which have historically always been defined by humans.
The key attribute of any of these models is the dynamics model, or how the world state x will evolve in response to the robot’s actions a. From this, all else follows: we can use a good dynamics model to plan over complex terrain and solve challenging symbol manipulation problems.
More recently, large language models have proven themselves to be reasonably good at this kind of thinking, but they remain unable to solve the symbol grounding problem which stymied the old-school planners: basically, what does it mean to “grasp a cup by the handle,” or “be careful, that’s hot,” or really convert symbolic instructions into measurable real-world values.
Fortunately, we have near infinite amounts of video data available to us in order to solve this symbol grounding problem now. And thus, world models.
Action-Conditioned World Models
Above: a screen recording of me using the Interactive World Models [11] online demo.
Action-conditioned world models predict a world state (usually a latent world state) given previous observations and robot actions. Examples include Interactive World Simulator [11], V-JEPA 2 [1], DREAMER v4 [2], and RISE [3]. Also notable is Genie 3 from Google, which generates scenes from a text prompt but then lets you explore them.
The main downside of these models is that they tend to be fairly local; errors accumulate rapidly, and they can’t do really long horizon reasoning. Even if they maintain physical consistency (which they increasingly do!), they will drift away from the real world.
I tend to think of this as the “purest” form of world model, and it is the oldest, despite its complexity and difficulty.
Alternate names:
learned simulation
JEPA-style model - technically a subset of action-conditioned world model which relies on specific tricks to prevent representation collapse when training on purely latent-state prediction without reconstruction
learned dynamics model (as in the end it’s modeling the changes in world state)
Video World Models with Inverse Dynamics
But these action-conditioned world models have a crucial weakness: they fail utterly at long horizons. Prediction quality degrades rapidly. They tend to fail at “long” horizons, even to the order of seconds (though this is getting much better; again see Interactive World Simulator [11] and try the demo).
Another more subtle issue is that they require action labels. Action labels are not available for most video data: we do not know how a human’s finger joints moved to pick up the cup, only what the results looked like.
And so we have a class of models which can take advantage of the massive corpus of video data to predict robot actions. They are “ordinary” video models, trained or fine-tuned on robot data, coupled with an “inverse dynamics model” which takes in successive states and predicts robot actions from them.
I tend to think of NVIDIA’s DreamGen [4] as one of the first outstanding examples in this category, which used video models and an “inverse dynamics model” to extract actions from a fine-tuned version of WAN, though they don’t directly execute the actions but instead used them to generate neural trajectories for training.
LingBot-VA [5] is a cool bridge between these models and our next category. During inference, it interleaves prediction of video frames with an inverse dynamics model which extracts actions from them, making it a hybrid between a pure video world model and a joint world-action model.
Watch the RoboPapers episode on the 1x world model, one example of this category. We also have a podcast on DreamGen.
Joint World Action Models
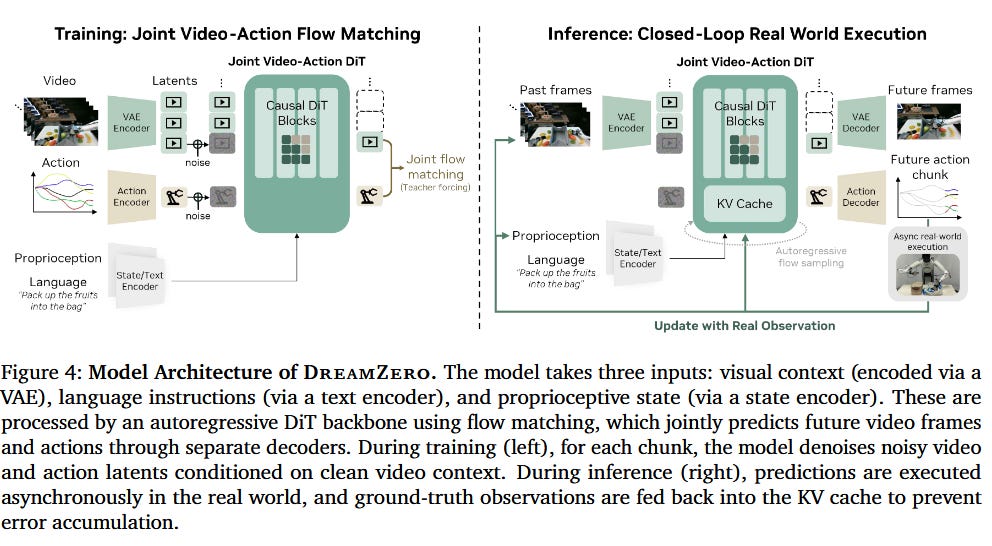
At different times, people have used the term “world action models” to refer to many things, but in this paper I’ll use it as used in DreamZero to describe the class of “joint world-action models” which predict both state and action without explicit conditioning.
These are probably the current “best” models, with chart-topping results in a couple benchmarks like RoboArena. They have the advantages of both world models (being able to train on and benefit from massive amounts of video) and VLAs (straightforward architecture, direct prediction of actions without jumping through a lot of hoops).
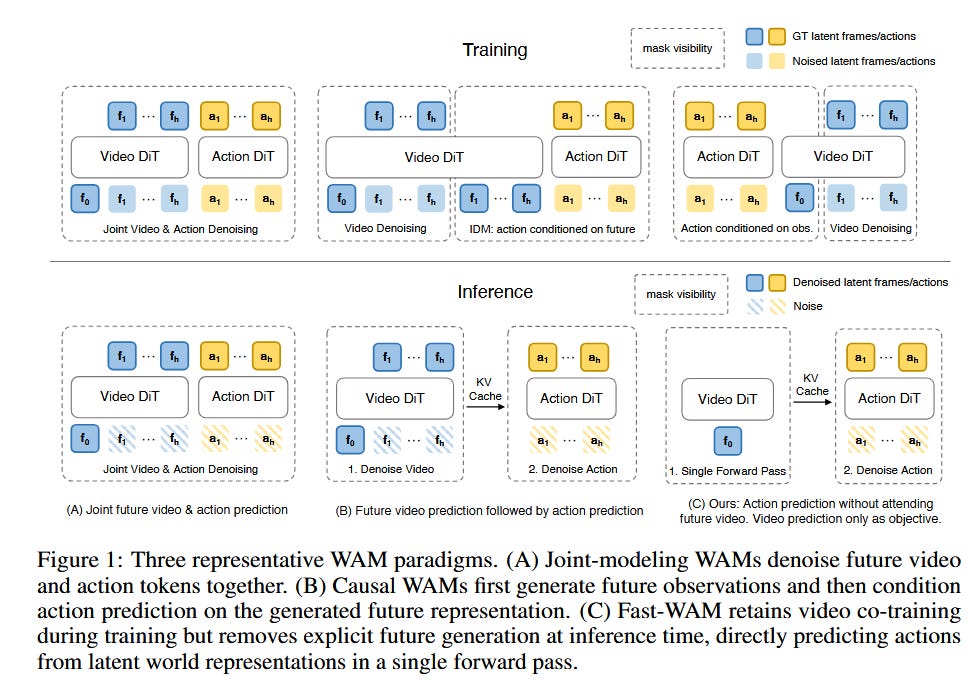
As per above: the main advantage here appears to be that these models can learn from video how the world should evolve implicitly, while still mostly predicting actions. There’s evidence (see Fast WAM [7], above), that decoding video is not at all a necessary step; DreamZero likewise does not decode video at test time, only at train time.
Watch our RoboPapers episode on DreamZero.
Bringing It Together
DualWorld takes the unique approach of combining the “video generation” approach with the much more local JEPA model. It uses a WAN 2.2 5B video generation backbone to predict high-level actions, then uses a JEPA model for local control to track these video references.
This is a cool approach because you can inject, for example, tactile and force information into the more local, short-horizon JEPA model, while getting all of the generalization advantages of the large pretrained video model. Perhaps approaches like this could result in a world model version of “system 1, system 2” reasoning and solve the issues with both approaches.
You can check out their video results here.
Final Thoughts
There are a ton of world model - focused companies out there, all with their own particular version of what a world model “is.” Many of these are not robotics focused. Moonlake AI, for example, raised $28 million in late 2025 to build game worlds, though they have grander ambitions. Yann LeCun’s Advanced Machine Intelligence raised a staggering $1.03 billion for world models, initially targeting smart glasses like Meta’s RayBans.
A note of caution is that world models have, historically, really underperformed expectations. They’re not a new idea, and especially action-conditioned world models have always struggled at producing real value. What’s changed is these things:
Models, especially video generation models, are much better
More data is now available for training these models
New architectures and improvements like video world models and the joint world action models described above
Interestingly, the disadvantages for all of these models are basically the same; as with many trendy methods like sim-to-real learning, they don’t yet achieve the high reliability that we see from on-robot reinforcement learning approaches like RL-100 or pi-0.6*. But this is likely to change, as this is an active area of research, and the models themselves seem so promising. More to come.
References
[1] Assran, M., et al. (2025). V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning. Meta FAIR.
[2] Hafner, D., et al. (2025). Training Agents Inside of Scalable World Models (DreamerV4).
[3] Yang, L., et al. (2026). RISE: Self-Improving Robot Policy with Compositional World Model.
[4] Jang, J., et al. (2025). DreamGen: Unlocking Generalization in Robot Learning through Neural Trajectories. NVIDIA GEAR Lab.
[5] Li, L., et al. (2026). Causal World Modeling for Robot Control (LingBot-VA). Robbyant.
[6] Ye, S., et al. (2026). DreamZero: World Action Models are Zero-shot Policies.
[7] Yuan, T., et al. (2026). Fast-WAM: Do World Action Models Need Test-time Future Imagination?
[8] Zhang, Q., et al. (2026). Do World Action Models Generalize Better than VLAs? A Robustness Study.
[9] Chao, Y.-W., et al. (2026). PointWorld: Scaling 3D World Models for In-The-Wild Robotic Manipulation.
[10] Fikes, R. E., & Nilsson, N. J. (1971). STRIPS: A New Approach to the Application of Theorem Proving to Problem Solving. Artificial Intelligence, 2(3-4), 189-208.
[11] Wang, Y., et al. (2025). Interactive World Simulator for Robot Policy Training and Evaluation. Columbia University, Toyota Research Institute, Amazon, UIUC.
Citations produced by Gemini from the text of this blog and may have errors.
Learn More
A great writeup from the Moonlake team on world models on X
Interactive World Models Paper by Yixuan Wang et al.
Dual world: https://world-mind.github.io/DualWorld/
Some previous blog posts and podcasts from me that you can read or listen to:
What are Robot World Models?

When humans want to perform new tasks, we start by envisioning the potential futures that may result from our actions. If I want to, say, cook a new recipe, I would start by thinking about which ingredients I need, how to set them out, and how to combine them. In doing so, I identify which tools and instruments I need for each step, catch any missing in…

Thank you for the great breakdown on world models! I just wrote about AI agents navigating the world of Minecraft, explaining their training methods, and how these actually mimic the behavior of children. I'd love to have your feedback if you are interested in reading about this: https://substack.com/home/post/p-191864960
Great summary! In terms of the categorization is it unfair to put the DualWorld thing roughly in the video model + inverse dynamics bucket? It seems to me to be similar but that the V-JEPA in that DualWorld is just more complex (working over a longer sequence and at a faster rate, potentially). Either way, decoupling the robot form and action head from the big video model is a helpful feature for generalizability for both of those categories, IMO.