


When humans want to perform new tasks, we start by envisioning the potential futures that may result from our actions. If I want to, say, cook a new recipe, I would start by thinking about which ingredients I need, how to set them out, and how to combine them. In doing so, I identify which tools and instruments I need for each step, catch any missing ingredients, and improve my likelihood of success.
Similarly, in “traditional” robot planning, we assume the existence of a dynamics model, which allows us to take the current state of the world and imagine a potential future. In classical symbolic planning — what we sometimes call STRIPS-style planning — these world states might look something like this:

This is a minimal, information-dense representation of a real robotic task. If I have the action “place X on Y”, though, I can replace X and Y with whichever objects I might care about, and generalize the task to new settings.
There are two main ways we can use these models:
Planning: generating potential futures for use planning; a sort of “test-time compute” for robotics. The quintessential papers here are works like PlaNet [1] and Deep Visual Foresight [2], which predate the modern generative AI era.
Data Generation: more recently, there’s been a push towards using video generative models - which are now amazingly capable - to generate data directly for robot learning.
This is a split between test-time compute (the planning use case) and train-time data augmentation (the data generation use case). Traditionally (meaning before 2020) the planning use case was far more prominent — but these days we’re usually more concerned with using it for data generation.
Why? Because of the robot data gap.
How can we get enough data to train a robot GPT?

It’s no secret that large language models are trained on massive amounts of data - many trillions of tokens. Even the largest robot datasets are quite far from this; in a year, Physical Intelligence collected about 10,000 hours worth of robot data to train their first foundation model, PI0. This is something Andra Keay
Robotics data are expensive and hard to collect. Good robotics data are substantially moreso: most robotics data collection programs have a fairly high rejection rate of data that gets collected and then “thrown out” for a variety of reasons. This means the data problem can actually be worse than it appears: collecting the right 10,000 hours of video data to train PiZero almost certainly took a lot longer than 10,000 hours.
This makes approaches that can leverage generative AI to create this data much more valuable. In this post, I’ll give an overview of what world models are, concretely, and look at the two primary use cases: planning and data generation.
Defining World Models
Above: an impressive example of a video world model from Zhiting Hu on Twitter/X.
When we discuss world models, we usually mean action-conditioned generative video models, or other generative video models focused on robotics applications. The largest and clearest difference between a robotics world model like the 1x World Model and a general-purpose video model like Veo3 is the application.
In principle, we could imagine a simulator as a learnable transition model:
next_state = world_model(state, action)But in this case, our “states” are going to be images, so it makes more sense to encode observations to a latent state first, then predict changes in latent space:
state = encode(observation) # From our training data
next_state = world_model(state, action)
next_observation = decode(observation) # Reconstruct image from training dataThis is the fundamental building block that most world models research is based on.
Another note: the colloquial use of the term “world model” is also quite different from the term “world representation,” which I’ve also used on this blog. When we use the term “world representation," we’re referring to the robot’s long-term memory: detailed 3d semantic maps, memory, retrieval-augmented generation.

World models are something different, usually focused at relatively short horizon generation. Although as context lengths grow, there’s no reason these two terms could not get closer together.
World Models for Planning

Planning improves generalization; it is, according to the Bitter Lesson, one of the two things that scales (with learning). The problem with planning is that it requires a useful forward model of the world, i.e. a model such that, if I give it an action, I can meaningfully differentiate between the quality of two different resulting outcomes in order to make a decision.
In most of the robotic planning literature, these models are very straightforward: either purely kinematic models (if the robot moves to position X, it will be at position X), or otherwise simplified, as in the STRIPS-style planning example at the beginning.
The problem is that these don’t really scale. Real-world robotics problems involve complex interactions with the environment that are not easily modeled. One of the first uses for generative world models, then, is for use during planning [1, 2].
The process goes something like this:
A policy generates a family of potential future trajectories
The world model rolls out these trajectories, generating a set of potential futures
You use some “value function” to determine which future is the best.
Why is this a good idea? At least in part, there’s a connection here to the kind of “test-time compute” used in modern reasoning models. By applying the generative model to the problem of generating potential futures, we don’t need our policy to implicitly capture every step.
A good recent example of this is the work Navigation World Models from Meta. It also reveals some of what makes these methods challenging to use in practice:
You need to be able to meaningfully sample different trajectories over long horizons, or the planning isn’t actually adding value
You need a good value function, which is actually really hard to compute in a novel, non-fully-observed environment
Horizons for video generative models tend to be fairly short; this is something you can sort of work around if you want to do symbolic planning (my first deep learning paper was on this!) but that involves a lot of engineering too.
We also see this in Meta’s V-JEPA 2 [8], which showed task execution in previously-unseen settings using its world model as a “planner.”
At 1x, they are initially using their world models partly for policy evaluation, which circumvents several of these issues, and provides a strong first step. Personally, I think this dream of scaling AI test-time compute to robotics is really exciting, but that it will take a while to get there — and that, importantly, we’ll still need a lot more robot data to do it.
So how can we get more data? Maybe world models can help with that.
World Models for Data Generation
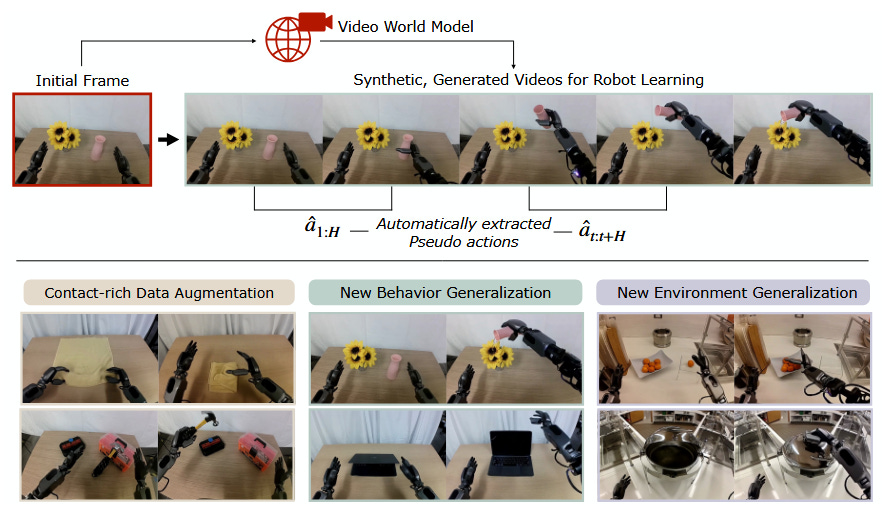
We’ve discussed the robot data gap in the past on this blog. To summarize:
Large language models like GPT are trained on (the equivalent of) billions of hours of data
The largest robots datasets that are of “machine learning” quality — not a trivial qualifier! — are on the order of tens of thousands of hours, not billions.
Collecting more data of machine learning quality is rather difficult. To effectively scale robot learning, we need diverse environments, diverse tasks, and so on. But video models are getting really, really good — see Veo3 — because they can leverage the tremendous amounts of non-robot data that exist out there.
And, so, we turn to world models. But still, there are a few important considerations, especially since we need to figure out how the data will be generated.
Remember, world models are generally action-conditioned:
next_state = world_model(state, action)Where the “action” is some parameterization of the robot skill, which means that we need some distribution to sample from (a policy, generally). We see this in the 1x Redwood world model, for example. When used as a part of a training process, this would often be what we describe as model-based reinforcement learning.

One good example is work from Tau Robotics, who uses model-based reinforcement learning with a learned world model to learn robot policies.
Now, this, unfortunately, has all of the downsides we associate with RL, most notably the difficulty with exploration and the fact that we need a good reward function. Model-based RL can be a powerful tool, but it’ll be mostly limited to a single environment.
One option that’s been growing in popularity is to, instead, use a more traditional language-and-image-conditioned video generative model. This is the approach we see in works like DreamGen [4], which used a fine-tuned version of WAN 2.1 to generate video of robot trajectories. Video generation models have a ton of applications in robotics, including pretraining [5].
This approach has tradeoffs which I will have to go into in a future post - but it has some significant advantages as well. By removing the need for a granular action sequence, the world model can better maintain consistency over a long horizon, and can leverage the oceans of human video data to generate examples of more complex and varied behaviors for robot training.
World Models in Practice
Comma.ai has a good writeup about how they use a world model to train their lane-keeping model, OpenPilot. They need a world model here because, while they have a lot of data, they don’t necessarily have the right data. Data collected from consumers is generally not i.i.d., something that makes scaling much more difficult. They need a simulator which allows the model to learn recovery behaviors from mistakes.
In their blog post, comma talks about why a simple reprojective simulator (basically, replaying the data you already had with some spatial tricks) doesn’t make the cut: it can’t handle dynamic scenes, there are too many artifacts, and the learners can pick up on and exploit these artifacts to learn nothing (i.e., cheat). Instead, they train a world model to act as a simple data-driven simulator for training a lane-keeping policy which works on real cars, in real driving scenarios.
You can also watch our RoboPapers episode with the CTO of Comma, Harald Schäfer.
Moving Past Video

Another interesting question we might ask is: do we need to stick to video?
Video is actually quite a limiting modality. If we’re rendering a camera from only a single point of view, we might miss details due to occlusions, for example. Works like DreamGen [4] get around this by predicting multiple videos tiled together, but this doesn’t exactly guarantee consistency or provide a mechanism for correction.
TesserAct [7] is an interesting paper which describes itself as a “4D world model,” meaning that it can predict full 3D scenes over time instead of just 2D video. This can be used for more complete data-driven simulation, and can be used to train policies that make use of valuable 3D data.
Final Thoughts
We’re constantly searching for ways to make models generalize better, and world models provide a couple vital ways in which we can do this. This is a short overview of these different research areas — one I hope to follow up on in the future.
The most important caveat to all of these is that they still require robot data; they are a multiplier, not a replacement, and in our “robot data” formula, we will still need to determine exactly how effective they might be, though early evidence is promising.
If you want to follow along, please like and subscribe.
Further Reading
1x Redwood World Model: a write-up from the prominent Norwegian-American humanoid robotics startup, discussing their work developing a world model.
Tau Robotics World Model: a write-up on the model-based RL approach developed by the startup Tau Robotics, builders of the famous Koch arms used by Huggingface.
I’ve previously written about how scaling laws apply to world models, according to some recent research:

I’ve also written about using generative AI for data collection:

References
[1] Hafner, D., Lillicrap, T., Fischer, I., Villegas, R., Ha, D., Lee, H., & Davidson, J. (2019, May). Learning latent dynamics for planning from pixels. In International conference on machine learning (pp. 2555-2565). PMLR. [ArXiV]
[2] Finn, C., & Levine, S. (2017, May). Deep visual foresight for planning robot motion. In 2017 IEEE international conference on robotics and automation (ICRA) (pp. 2786-2793). IEEE. [PDF]
[3] Bar, A., Zhou, G., Tran, D., Darrell, T., & LeCun, Y. (2025). Navigation world models. In Proceedings of the Computer Vision and Pattern Recognition Conference (pp. 15791-15801). [website]
[4] Jang, J., Ye, S., Lin, Z., Xiang, J., Bjorck, J., Fang, Y., ... & Fan, L. (2025). DreamGen: Unlocking Generalization in Robot Learning through Neural Trajectories. arXiv e-prints, arXiv-2505. [ArXiV]
[5] Wu, H., Jing, Y., Cheang, C., Chen, G., Xu, J., Li, X., ... & Kong, T. (2023). Unleashing large-scale video generative pre-training for visual robot manipulation. arXiv preprint arXiv:2312.13139.
[6] Goff, M., Hogan, G., Hotz, G., du Parc Locmaria, A., Raczy, K., Schäfer, H., ... & Yousfi, Y. (2025). Learning to drive from a world model. In Proceedings of the Computer Vision and Pattern Recognition Conference (pp. 1964-1973).
[7] Zhen, H., Sun, Q., Zhang, H., Li, J., Zhou, S., Du, Y., & Gan, C. (2025). TesserAct: learning 4D embodied world models. arXiv preprint arXiv:2504.20995.
[8] Assran, M., Bardes, A., Fan, D., Garrido, Q., Howes, R., Muckley, M., ... & Ballas, N. (2025). V-jepa 2: Self-supervised video models enable understanding, prediction and planning. arXiv preprint arXiv:2506.09985.
Robot world models sound cool and all, but they’re just not there yet. For a taste of what's possible, check out this:https://www.ainanobanana.pro